











基本概念
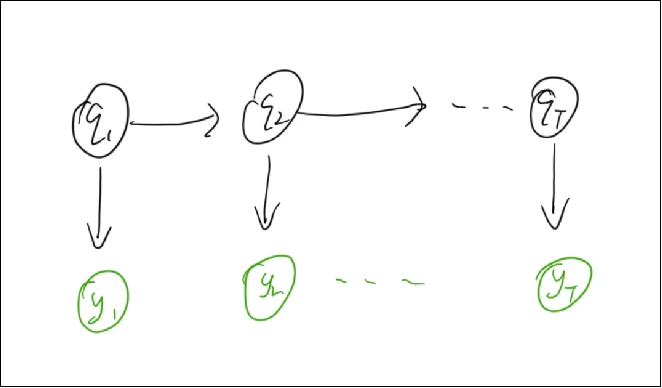
为隐状态, 为观测值。上图描述的是这样一件事情:假设在某个系统中,按照时间序列可以分为若干时间节点。在每一个时刻,我们可以通过观测得到一个结果(观测值 ),相应的,该时刻也存在一个隐状态 。但这个观测值/隐状态发生的概率,和非常多的因素都有关系,例如之前时刻的历史观测值、历史状态、还有当前时刻的状态,因此非常难以求解。
隐状态,顾名思义,是一个我们是无法观测到的、隐藏起来的状态值。例如对于当前的股市,到底是牛市还是低谷,谁也不知道。因为并没有一个明确的指标,或者某个事物可以直接观测股市所处的状态,但股市的状态显然会影响到股价,因此“牛市 or 低谷”就是一个隐状态,而“股价”就是我们的观测值。
基于此,我们做出如下两个定义:
- 转移概率(transition probability): ,从上一个时刻 t-1 时的状态,转移到当前时间 t 所处的状态的概率
- 发射概率(emission probability): ,已知当前隐状态,观测时的概率
两个假设
齐次马尔可夫假设:任意时刻的隐状态只依赖前一时刻的隐状态,与其他时刻的状态和观测值无关即
Discrete Transition Probability
观测独立性假设:任意时刻的观测值只依赖当前时刻的隐状态,与其他状态及观测值无关即
Continous/Discrete Measurement probability
从同一个状态 转移到其他状态时,所有的转移概率,加起来和应该为 1。
这两个假设的作用,就是为了简化上文中,那个“和非常多的因素都有关系”的概率计算问题。
隐马尔可夫模型三要素
这个等式是基于全概率公式的推导。假设有三个事件 y1、y2和 y3,以及三个条件事件(隐状态) q1、q2和 q3。根据全概率公式,我们可以将事件 y1、y2和 y3的联合概率表示为对条件事件 q1、q2和 q3的求和。
首先,我们可以将向事件 y1、y2和 y3 添加隐状态 q1、q2和 q3:
p(y1, y2, y3) = p(y1, y2, y3, q1, q2, q3)然后,根据全概率公式,我们可以将联合概率表示为对其所有可能取值的求和。在这个特定的情况下,条件事件 q1、q2和 q3都有 k 个可能的取值,因此我们需要对 q1、q2和 q3 分别进行求和。
这里的求和符号 表示对所有可能取值的求和!!!
WARNING切记这个设定,不然你下面推导的时候,会一直怀疑人生:“ 为什么一定是从 1 到 K 的整数取值?”
注意,下文中的很多符号,都会和你们最容易搜索到的(李航《统计学习方法》)有所不同,目的是为了简化符号表达,便于理解。但其本质都是类似的,建议可以对比学习一下。
其中,
这一段做一些说明。(1)到(2)和(2)到(3)分别使用了 HMM 的观测独立性假设和齐次马尔可夫假设。等推导出(3)时,不难发现,式子进入了迭代状态,或者说剩下的 可以利用上面的操作如法炮制。总之,最后可以化简为下式
规定
其中, 的概率是已知的,即发射概率矩阵 B(由本文开头定义的那个发射概率所组成的一个矩阵,转移概率矩阵与之同理); 的概率也已知,即转移概率矩阵 A。那 是多少呢?
对于转移概率矩阵 A, 的条件和概率其实分别给出了矩阵对应的行和列。例如 对应的就是矩阵 A 的 i 行 j 列取值,即 。
隐马尔可夫模型三要素,The HMM Parameter contains:
其中, 就是初始状态概率向量 ,或者叫初始概率分布,也就是上面式子中最后一个未知项 。
所以进一步,我们可以总结一下
转移概率 ,发射概率
那么这长长的一串求了一个什么玩意呢?其实就是 HMM 的一个应用场景,即 ,也就是预估事件 Y 的概率 。
显然,由于 sum (求和)太多, 的取值会有 种。这个数值实在过于庞大,因此我们需要更简单的计算方法。
前向算法
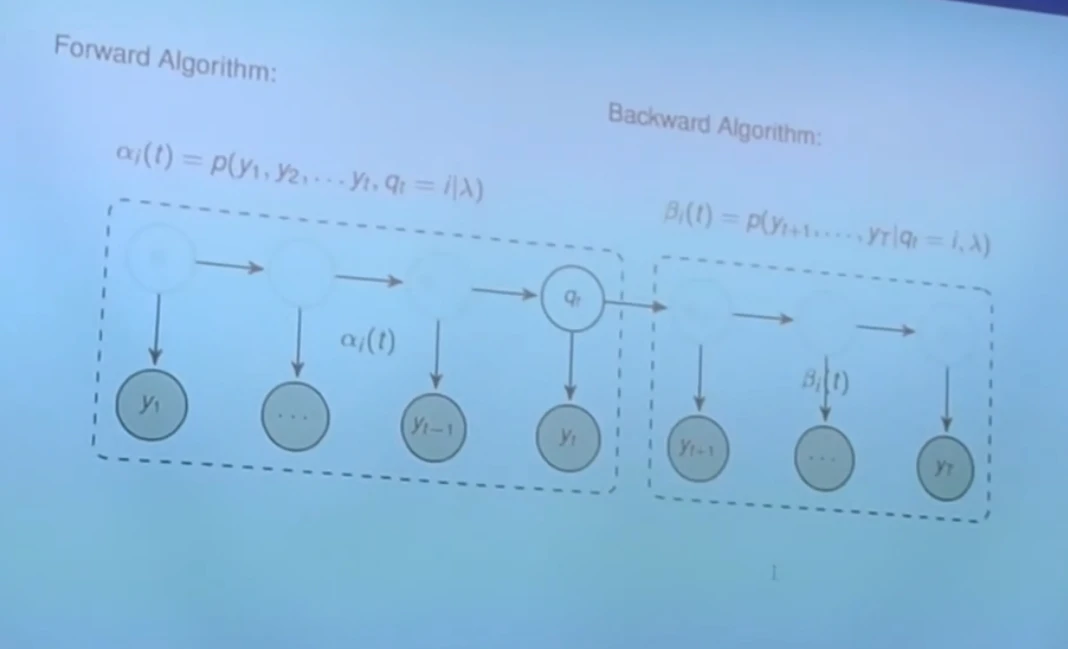
算法推导
首先,我们来定义一个前向概率:
其中, 指的是已知 ,当时间 t 时,状态 的值为 时, 和截至时间 t 为止所有观测值的联合概率。
这不涉及什么数学问题,仅仅是做出了这么一个定义。那么这玩意如何帮助我们解决上面那个复杂计算的问题呢?
假设当 t=1 时,状态为
这里的 就省略不写了
再来看一个,假设当 t=2 时,状态为
发现没,最后一行的 ,不就是 吗?
接着上面的继续推
oh,爷の上帝,瞧瞧出现了什么!又是 TMD 递归!
根据这个规律不难看出,每个 都对应 K 个 sum,因此总共只需要计算 ,比 小多了。
依据 的定义,
因此,我们所求的 跟上式就差了一个 而已,那么按照老方法,我们把 塞进去,再积分积掉
上面这个推导过程,其实就是 HMM 的 Forward Algorithm(前向算法)
当然,有 forward 就有 backward,不过两者求出的概率是一样的
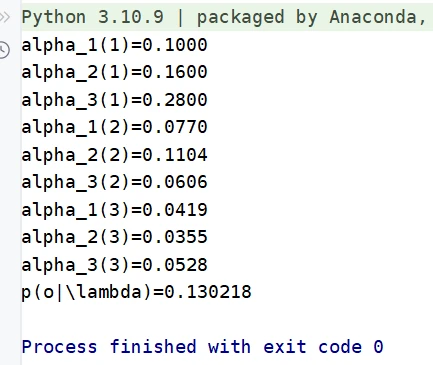
代码实现
import numpy as np
def forward(A, B, PI, observation, only_r = True): """观测序列概率的前向算法""" n_state = len(A) # 可能的状态数 T = len(observation) alpha = np.zeros((T, n_state))
# 初始化前向概率 for i in range(n_state): alpha[0][i] = PI[i] * B[i][observation[0]]
# 递推计算前向概率 for t in range(1, T): for i in range(n_state): alpha[t][i] = np.dot(alpha[t-1], [a[i] for a in A]) * B[i][observation[t]]
if not only_r: return alpha.tolist()
return np.sum(alpha[len(alpha)-1])后向算法
还是先定义后向概率
指的是已知 和 的值为 ,未来的观测值的联合概率。
规定, (所以上述推导中,乘 1 不影响结果)。这是相邻两个后向概率的递推式。那么我们最后要求的
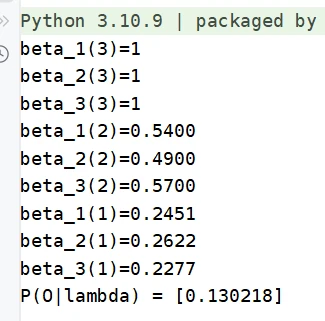
代码实现
def backward(A, B, PI, observation, only_r = True): """观测序列概率的后向算法""" n_state = len(A) # 可能的状态数 T = len(observation)
# 初始化后向概率 beta = np.ones((T, n_state))
# 递推(状态转移) for t in range(len(observation) - 2, -1, -1): for i in range(n_state): beta[t][i] = np.dot( np.multiply(A[i], [b[observation[t+1]] for b in B]), beta[t+1] )
if not only_r: return beta.tolist()
return np.dot( np.multiply(PI, [b[observation[0]] for b in B]), beta[0] )两种算法结果一致
参考李航《统计学习方法》 https://github.com/sun2ot/python-study/blob/main/model/HMM.py
Baum-Welch 算法
假设我们只能获取观测序列 ,但无法获取对应的状态序列,则可以通过 BW 算法学习出 HMM 的参数 。
[!bug] EM 算法的推理过程还没看懂,这里暂时只能根据数学公式的结果给出实现代码。

def baum_welch(observation, n_state, max_iter=100): """Baum-Welch算法学习隐马尔可夫模型
:param observation: 观测序列 :param n_state: 可能的状态数 :param max_iter: 最大迭代次数 :return: A,B,π """ T = len(observation) # 样本数 n_observation = len(set(observation)) # 可能的观测数
# ---------- 初始化随机模型参数 ---------- # 初始化状态转移概率矩阵 a = np.random.rand(n_state, n_state) a /= np.sum(a, axis=1, keepdims=True)
# 初始化观测概率矩阵 b = np.random.rand(n_state, n_observation) b /= np.sum(b, axis=1, keepdims=True)
# 初始化初始状态概率向量 p = np.random.rand(n_state) p /= np.sum(p)
for _ in range(max_iter): # 计算前向概率 alpha = forward(a,b,p,observation, only_r=False) # 计算后向概率 beta = backward(a,b,p,observation, only_r=False)
beta.reverse()
# ---------- 计算:\gamma_t(i) ---------- gamma = [] for t in range(T): lst = np.zeros(n_state) for i in range(n_state): lst[i] = alpha[t][i] * beta[t][i] sum_ = np.sum(lst) lst /= sum_ gamma.append(lst)
# ---------- 计算:\xi_t(i,j) ---------- xi = [] for t in range(T - 1): sum_ = 0 lst = [[0.0] * n_state for _ in range(n_state)] for i in range(n_state): for j in range(n_state): lst[i][j] = alpha[t][i] * a[i][j] * b[j][observation[t + 1]] * beta[t + 1][j] sum_ += lst[i][j] for i in range(n_state): for j in range(n_state): lst[i][j] /= sum_ xi.append(lst)
# ---------- 计算新的状态转移概率矩阵 ---------- new_a = [[0.0] * n_state for _ in range(n_state)] for i in range(n_state): for j in range(n_state): # 分子,分母 numerator, denominator = 0, 0 for t in range(T - 1): numerator += xi[t][i][j] denominator += gamma[t][i] new_a[i][j] = numerator / denominator
# ---------- 计算新的观测概率矩阵 ---------- new_b = [[0.0] * n_observation for _ in range(n_state)] for j in range(n_state): for k in range(n_observation): numerator, denominator = 0, 0 for t in range(T): if observation[t] == k: numerator += gamma[t][j] denominator += gamma[t][j] new_b[j][k] = numerator / denominator
# ---------- 计算新的初始状态概率向量 ---------- new_p = [1 / n_state] * n_state for i in range(n_state): new_p[i] = gamma[0][i]
a, b, p = new_a, new_b, new_p return a, b, p测试数据如下
sequence = [0, 1, 1, 0, 0, 1]
A = [[0.0, 1.0, 0.0, 0.0], [0.4, 0.0, 0.6, 0.0], [0.0, 0.4, 0.0, 0.6], [0.0, 0.0, 0.5, 0.5]]B = [[0.5, 0.5], [0.3, 0.7], [0.6, 0.4], [0.8, 0.2]]PI = [0.25, 0.25, 0.25, 0.25]
alpha = forward(A, B, PI, sequence)print("初始模型参数:", alpha)
A1,B1,P1 = baum_welch(sequence, 4, max_iter=1000)alpha2 = forward(A1, B1, P1, sequence)print("BN算法训练后:", alpha2)如果这篇文章对你有帮助,欢迎分享给更多人!
部分信息可能已经过时
