











394 字
1 分钟
WSL 部署 CosyVoice3
环境配置
TIP大体过程可以完全参考官方的 README 文档
首先克隆官方仓库:
git clone https://github.com/FunAudioLLM/CosyVoice.git如果网络问题导致克隆中断,可以进入项目路径后重新执行:
cd CosyVoicegit submodule update --init --recursive配置虚拟环境的工具,官方给出的是 conda,我这里使用 pixi 替代:
pixi initpixi add python=3.10pixi.toml 和 pixi.lock 参见 https://gist.github.com/sun2ot/c3e0802ccc0c706664a7a501b4d7251e
WARNING我的环境为:Windows 11 23H2,WSL Ubuntu-24.04 LTS,Nvidia Driver 591.86,CUDA 13.1 依赖版本仅供参考
将环境配置文件内容复制替换后,执行 pixi install 即可。
预训练模型下载
参考官方文档中的 Model download 部分,按照国内外不同网络环境使用脚本下载即可。例如国内环境下,创建 model_dl.py 文件:
from modelscope import snapshot_downloadsnapshot_download('FunAudioLLM/Fun-CosyVoice3-0.5B-2512', local_dir='pretrained_models/Fun-CosyVoice3-0.5B')snapshot_download('iic/CosyVoice2-0.5B', local_dir='pretrained_models/CosyVoice2-0.5B')snapshot_download('iic/CosyVoice-300M', local_dir='pretrained_models/CosyVoice-300M')snapshot_download('iic/CosyVoice-300M-SFT', local_dir='pretrained_models/CosyVoice-300M-SFT')snapshot_download('iic/CosyVoice-300M-Instruct', local_dir='pretrained_models/CosyVoice-300M-Instruct')snapshot_download('iic/CosyVoice-ttsfrd', local_dir='pretrained_models/CosyVoice-ttsfrd')然后执行 python model_dl.py 即可。所有模型总共需占用 32G,如果仅需要音色克隆,则只需下载 FunAudioLLM/Fun-CosyVoice3-0.5B-2512 即可(可能是的,我没试过)。
代码修改
由于 torchaudio 与官方版本不一致,因此导致 .info() API 存在不兼容。修改 webui.py 如下内容即可:
if mode_checkbox_group in ['3s极速复刻', '跨语种复刻']: if prompt_wav is None: gr.Warning('prompt音频为空,您是否忘记输入prompt音频?') yield (cosyvoice.sample_rate, default_data) waveform, sr = torchaudio.load(prompt_wav) # if torchaudio.info(prompt_wav).sample_rate < prompt_sr: if sr < prompt_sr: # gr.Warning('prompt音频采样率{}低于{}'.format(torchaudio.info(prompt_wav).sample_rate, prompt_sr)) gr.Warning(f'prompt音频采样率{sr}低于{prompt_sr}') yield (cosyvoice.sample_rate, default_data)启动
终端执行 python webui.py --model_dir pretrained_models/Fun-CosyVoice3-0.5B,启动后访问 http://localhost:8000 即可看到 webui 界面。
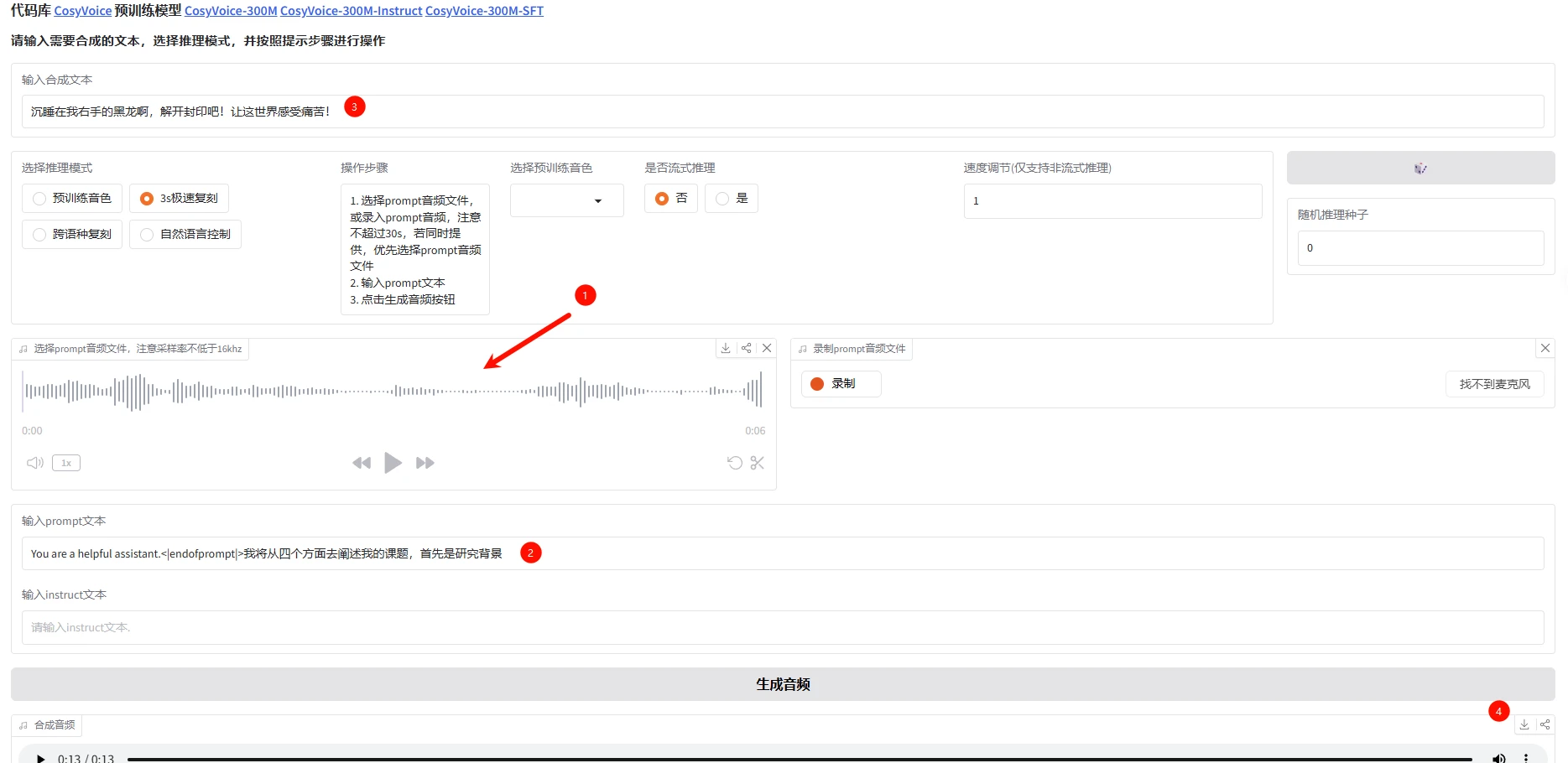
注意两个问题:
- 音色克隆除了音源以外,还需要对应的标签,即与音频对应的文本。但由于是零样本生成,因此准备几秒的音频即可,手动录入文本标签并不会很困难。
prompt文本可能存在 bug,参考 issue1703,要在你的提示词前面加上You are a helpful assistant.<|endofprompt|>,否则亲测会报错。
WSL 部署 CosyVoice3
https://blog.085404.xyz/posts/cosyvoice3/ 部分信息可能已经过时
