基本概念
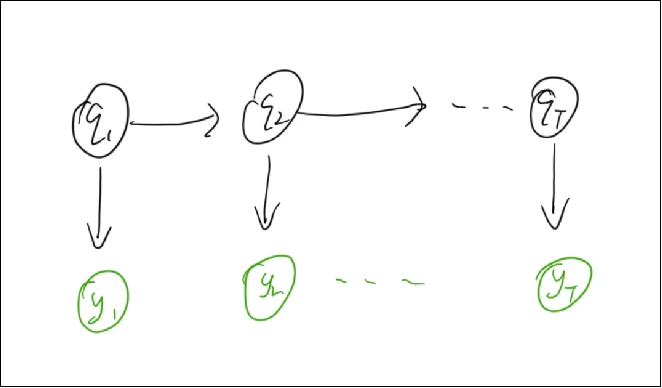
q q q y y y y y y q q q
隐状态 ,顾名思义,是一个我们是无法观测到的、隐藏起来的状态值。例如对于当前的股市,到底是牛市还是低谷,谁也不知道。因为并没有一个明确的指标,或者某个事物可以直接观测股市所处的状态,但股市的状态显然会影响到股价,因此“牛市 or 低谷”就是一个隐状态,而“股价”就是我们的观测值。
基于此,我们做出如下两个定义:
转移概率 (transition probability): P ( q t ∣ q t − 1 ) P(q_t|q_{t-1}) P ( q t ∣ q t − 1 ) 发射概率 (emission probability): P ( y t ∣ q t ) P(y_t|q_t) P ( y t ∣ q t )
两个假设
齐次马尔可夫假设 :任意时刻的隐状态只依赖前一时刻的隐状态,与其他时刻的状态和观测值无关即
P ( q t ∣ q 1 , . . . q t − 1 , y 1 , . . . , y t − 1 ) = P ( q t ∣ q t − 1 ) P(q_t|q_1,...q_{t-1},y_1,...,y_{t-1}) = P(q_t|q_{t-1})
P ( q t ∣ q 1 , ... q t − 1 , y 1 , ... , y t − 1 ) = P ( q t ∣ q t − 1 )
Discrete Transition Probability
观测独立性假设 :任意时刻的观测值只依赖当前时刻的隐状态,与其他状态及观测值无关即
P ( y t ∣ q 1 , . . . q t − 1 , q t , y 1 , . . . , y t − 1 ) = P ( y t ∣ q t ) P(y_t|q_1,...q_{t-1},q_t,y_1,...,y_{t-1}) = P(y_t|q_t)
P ( y t ∣ q 1 , ... q t − 1 , q t , y 1 , ... , y t − 1 ) = P ( y t ∣ q t )
Continous/Discrete Measurement probability
从同一个状态 q t − 1 q_{t-1} q t − 1
这两个假设的作用,就是为了简化上文中,那个“和非常多的因素都有关系”的概率计算问题。
隐马尔可夫模型三要素
P ( y 1 , y 2 , y 3 ) = ∑ q 1 = 1 k ∑ q 2 = 1 k ∑ q 3 = 1 k P ( y 1 , y 2 , y 3 , q 1 , q 2 , q 3 ) P(y_1,y_2,y_3)=\displaystyle{\sum_{q_1=1}^k \sum_{q_2=1}^k \sum_{q_3=1}^k P(y_1,y_2,y_3,q_1,q_2,q_3)}
P ( y 1 , y 2 , y 3 ) = q 1 = 1 ∑ k q 2 = 1 ∑ k q 3 = 1 ∑ k P ( y 1 , y 2 , y 3 , q 1 , q 2 , q 3 )
这个等式是基于全概率公式 的推导。假设有三个事件 y1、y2和 y3,以及三个条件事件(隐状态) q1、q2和 q3。根据全概率公式,我们可以将事件 y1、y2和 y3的联合概率表示为对条件事件 q1、q2和 q3的求和。
首先,我们可以将向事件 y1、y2和 y3 添加隐状态 q1、q2和 q3:
1 p(y1, y2, y3) = p(y1, y2, y3, q1, q2, q3)
然后,根据全概率公式,我们可以将联合概率表示为对其所有可能取值的求和。在这个特定的情况下,条件事件 q1、q2和 q3都有 k 个可能的取 值,因此我们需要对 q1、q2和 q3 分别进行求和。
这里的求和符号 ∑ \sum ∑
[!warning]q t q_t q t
注意,下文中的很多符号,都会和你们最容易搜索到的(李航《统计学习方法》)有所不同,目的是为了简化符号表达,便于理解。但其本质都是类似的,建议可以对比学习一下。
其中,
P ( y 1 , y 2 , y 3 , q 1 , q 2 , q 3 ) = P ( y 3 ∣ y 1 , y 2 , q 1 , q 2 , q 3 ) × P ( y 1 , y 2 , q 1 , q 2 , q 3 ) = P ( y 3 ∣ q 3 ) × P ( q 3 ∣ y 1 , y 2 , q 1 , q 2 ) × P ( y 1 , y 2 , q 1 , q 2 ) = P ( y 3 ∣ q 3 ) × P ( q 3 ∣ q 2 ) × P ( y 1 , y 2 , q 1 , q 2 ) = ⋯ \begin{align}
&P(y_1,y_2,y_3,q_1,q_2,q_3) \\ \tag1
=&P(y_3|y_1,y_2,q_1,q_2,q_3) \times P(y_1,y_2,q_1,q_2,q_3) \\ \tag2
=&P(y_3|q_3) \times P(q_3|y_1,y_2,q_1,q_2) \times P(y_1,y_2,q_1,q_2) \\ \tag3
=&P(y_3|q_3) \times P(q_3|q_2) \times P(y_1,y_2,q_1,q_2) \\
=&\dotsb
\end{align}
= = = = P ( y 1 , y 2 , y 3 , q 1 , q 2 , q 3 ) P ( y 3 ∣ y 1 , y 2 , q 1 , q 2 , q 3 ) × P ( y 1 , y 2 , q 1 , q 2 , q 3 ) P ( y 3 ∣ q 3 ) × P ( q 3 ∣ y 1 , y 2 , q 1 , q 2 ) × P ( y 1 , y 2 , q 1 , q 2 ) P ( y 3 ∣ q 3 ) × P ( q 3 ∣ q 2 ) × P ( y 1 , y 2 , q 1 , q 2 ) ⋯ ( 1 ) ( 2 ) ( 3 )
这一段做一些说明。(1)到(2)和(2)到(3)分别使用了 HMM 的观测独立性假设 和齐次马尔可夫假设 。等推导出(3)时,不难发现,式子进入了迭代状态,或者说剩下的 P ( y 1 , y 2 , q 1 , q 2 ) P(y_1,y_2,q_1,q_2) P ( y 1 , y 2 , q 1 , q 2 )
P ( y 3 ∣ q 3 ) × P ( q 3 ∣ q 2 ) × P ( y 2 ∣ q 2 ) × P ( q 2 ∣ q 1 ) × P ( y 1 ∣ q 1 ) × P ( q 1 ) P(y_3|q_3) \times P(q_3|q_2) \times P(y_2|q_2) \times P(q_2|q_1) \times P(y_1|q_1) \times P(q_1)
P ( y 3 ∣ q 3 ) × P ( q 3 ∣ q 2 ) × P ( y 2 ∣ q 2 ) × P ( q 2 ∣ q 1 ) × P ( y 1 ∣ q 1 ) × P ( q 1 )
规定 P ( q 1 ∣ q 0 ) = P ( q 1 ) P (q_1|q_0) = P(q_1) P ( q 1 ∣ q 0 ) = P ( q 1 )
其中, P ( y t ∣ q t ) P(y_t|q_t) P ( y t ∣ q t ) P ( q t ∣ q t − 1 ) P(q_t|q_{t-1}) P ( q t ∣ q t − 1 ) P ( q 1 ) P(q_1) P ( q 1 )
对于转移概率矩阵 A, P ( q t ∣ q t − 1 ) P(q_t|q_{t-1}) P ( q t ∣ q t − 1 ) P ( q t = j ∣ q t − 1 = i ) P(q_t=j|q_{t-1}=i) P ( q t = j ∣ q t − 1 = i ) a i , j a_{i,j} a i , j
隐马尔可夫模型三要素 ,The HMM Parameter λ \lambda λ
λ = { A , B , π } \lambda = \{A,B,\pi\}
λ = { A , B , π }
其中, π \pi π π i = P ( q 1 = i 1 , 2 , . . . , K ) \pi_i = P (q_1=i_{1,2,...,K}) π i = P ( q 1 = i 1 , 2 , ... , K ) P ( q 1 ) P(q_1) P ( q 1 )
所以进一步,我们可以总结一下
P ( Y ∣ λ ) = ∑ Q [ P ( Y , Q ∣ λ ) ] = ∑ q 1 = 1 k ⋯ ∑ q T = 1 k [ P ( y 1 , . . . , y T , q 1 , . . . q T ∣ λ ) ] = ∑ q 1 = 1 k ⋯ ∑ q T = 1 k [ P ( y 1 , . . . , y T , q 0 , q 1 , . . . q T ∣ λ ) ] = ∑ q 1 = 1 k ⋯ ∑ q T = 1 k P ( q 1 ) P ( y 1 ∣ q 1 ) P ( q 2 ∣ q 1 ) ⋯ P ( q t ∣ q t − 1 ) P ( y t ∣ q t ) = ∑ q 1 = 1 k ⋯ ∑ q T = 1 k π ( q 1 ) ∏ t = 2 T a q t − 1 , q t b q t ( y t ) \begin{align}
P(Y|\lambda) &= \displaystyle{\sum_Q[P(Y,Q|\lambda)]} \\
&= \displaystyle{\sum_{q_1=1}^k \dotsb \sum_{q_T=1}^k}[P(y_1,...,y_{T},q_1,...q_T|\lambda)] \\
&= \displaystyle{\sum_{q_1=1}^k \dotsb \sum_{q_T=1}^k}[P(y_1,...,y_{T},q_0,q_1,...q_T|\lambda)] \\
&= \displaystyle{\sum_{q_1=1}^k \dotsb \sum_{q_T=1}^k} P(q_1)P(y_1|q_1)P(q_2|q_1) \dotsb P(q_t|q_{t-1})P(y_t|q_t) \\
&= \displaystyle{\sum_{q_1=1}^k \dotsb \sum_{q_T=1}^k \pi(q_1) \prod_{t=2}^Ta_{q_{t-1},q_t}\,b_{q_t}(y_t)}
\end{align}
P ( Y ∣ λ ) = Q ∑ [ P ( Y , Q ∣ λ )] = q 1 = 1 ∑ k ⋯ q T = 1 ∑ k [ P ( y 1 , ... , y T , q 1 , ... q T ∣ λ )] = q 1 = 1 ∑ k ⋯ q T = 1 ∑ k [ P ( y 1 , ... , y T , q 0 , q 1 , ... q T ∣ λ )] = q 1 = 1 ∑ k ⋯ q T = 1 ∑ k P ( q 1 ) P ( y 1 ∣ q 1 ) P ( q 2 ∣ q 1 ) ⋯ P ( q t ∣ q t − 1 ) P ( y t ∣ q t ) = q 1 = 1 ∑ k ⋯ q T = 1 ∑ k π ( q 1 ) t = 2 ∏ T a q t − 1 , q t b q t ( y t )
转移概率 P ( q t = j ∣ q t − 1 = i ) ⟹ a i , j P (q_t=j|q_{t-1}=i) \implies a_{i,j} P ( q t = j ∣ q t − 1 = i ) ⟹ a i , j P ( y t ∣ q t = j ) ⟹ b j ( y t ) P (y_t|q_t=j) \implies b_j(y_t) P ( y t ∣ q t = j ) ⟹ b j ( y t )
那么这长长的一串求了一个什么玩意呢?其实就是 HMM 的一个应用场景,即 E v a l u a t e P ( Y ∣ λ ) Evaluate\;P(Y|\lambda) E v a l u a t e P ( Y ∣ λ ) p ( y 1 , . . . , y T ) p(y_1,...,y_T) p ( y 1 , ... , y T )
显然,由于 sum (求和)太多, Q Q Q K T K^T K T
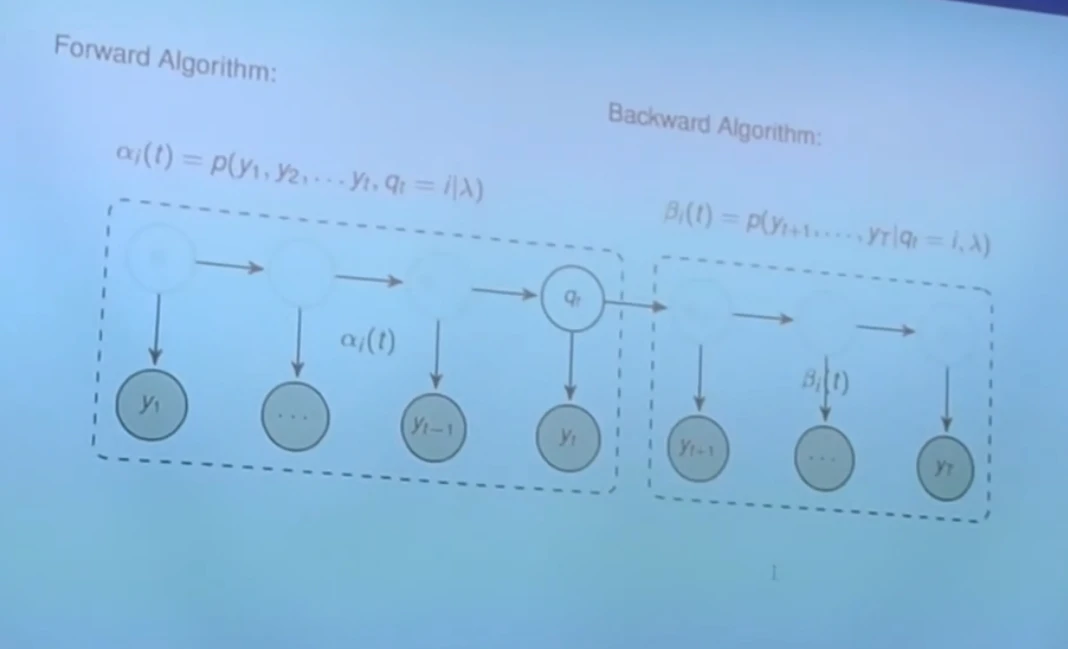
前向算法
算法推导
首先,我们来定义一个前向概率 :
α i ( t ) = p ( y 1 , . . . , y t , q t = i ∣ λ ) \begin{align}
\alpha_i(t) = p(y_1,...,y_t,q_t=i|\lambda)
\end{align}
α i ( t ) = p ( y 1 , ... , y t , q t = i ∣ λ )
其中, α i ( t ) \alpha_i(t) α i ( t ) λ \lambda λ q t q_t q t i i i q t q_t q t
这不涉及什么数学问题,仅仅是做出了这么一个定义。那么这玩意如何帮助我们解决上面那个复杂计算的问题呢?
假设当 t=1 时,状态为 i i i
α i ( 1 ) = p ( y 1 , q 1 = i ) = p ( y 1 ∣ q 1 = i ) p ( q 1 ) = b i ( y 1 ) π ( q 1 ) \alpha_i(1) = p(y_1,q_1=i) = p(y_1|q_1=i)p(q_1) = b_i(y_1)\pi(q_1)
α i ( 1 ) = p ( y 1 , q 1 = i ) = p ( y 1 ∣ q 1 = i ) p ( q 1 ) = b i ( y 1 ) π ( q 1 )
这里的 λ \lambda λ
再来看一个,假设当 t=2 时,状态为 j j j
α j ( 2 ) = p ( y 1 , y 2 , q 2 = j ) = ∑ i = 1 K p ( y 1 , y 2 , q 1 = i , q 2 = j ) = ∑ i = 1 K p ( y 2 ∣ q 2 = j ) p ( q 2 = j ∣ q 1 = i ) p ( y 1 , q 1 = i ) \begin{align}
\alpha_j(2) &= p(y_1,y_2,q_2=j) \\
&= \displaystyle{\sum_{i=1}^K p(y_1,y_2,q_1=i,q_2=j)} \\
&= \displaystyle{\sum_{i=1}^K p(y_2|q_2=j)p(q_2=j|q_1=i)p(y_1,q_1=i)}
\end{align}
α j ( 2 ) = p ( y 1 , y 2 , q 2 = j ) = i = 1 ∑ K p ( y 1 , y 2 , q 1 = i , q 2 = j ) = i = 1 ∑ K p ( y 2 ∣ q 2 = j ) p ( q 2 = j ∣ q 1 = i ) p ( y 1 , q 1 = i )
发现没,最后一行的 p ( y 1 , q 1 = i ) p(y_1,q_1=i) p ( y 1 , q 1 = i ) α i ( 1 ) \alpha_i(1) α i ( 1 )
接着上面的继续推
= ∑ i = 1 K p ( y 2 ∣ q 2 = j ) p ( q 2 = j ∣ q 1 = i ) p ( y 1 , q 1 = i ) = p ( y 2 ∣ q 2 = j ) ∑ i = 1 K [ p ( q 2 = j ∣ q 1 = i ) α i ( 1 ) ] = b j ( y 2 ) [ ∑ i = 1 K a i , j α i ( 1 ) ] \begin{align}
&= \displaystyle{\sum_{i=1}^K p(y_2|q_2=j)p(q_2=j|q_1=i)p(y_1,q_1=i)} \\
&= p(y_2|q_2=j)\,\displaystyle{\sum_{i=1}^K [p(q_2=j|q_1=i)\alpha_i(1)]} \\
&= b_j(y_2) [\sum_{i=1}^K a_{i,j}\alpha_i(1)]
\end{align}
= i = 1 ∑ K p ( y 2 ∣ q 2 = j ) p ( q 2 = j ∣ q 1 = i ) p ( y 1 , q 1 = i ) = p ( y 2 ∣ q 2 = j ) i = 1 ∑ K [ p ( q 2 = j ∣ q 1 = i ) α i ( 1 )] = b j ( y 2 ) [ i = 1 ∑ K a i , j α i ( 1 )]
oh,爷の上帝,瞧瞧出现了什么!又是 TMD 递归!
α j ( T ) = b j ( y T ) [ ∑ i = 1 K a i , j α i ( T − 1 ) ] \alpha_j(T) = b_j(y_T) \displaystyle{[\sum_{i=1}^K a_{i,j} \alpha_i(T-1)]}
α j ( T ) = b j ( y T ) [ i = 1 ∑ K a i , j α i ( T − 1 )]
根据这个规律不难看出,每个 α \alpha α K ⋅ T K \cdot T K ⋅ T K T K^T K T
依据 α \alpha α
α j ( T ) = p ( y 1 , . . . , y T , q T = j ) \alpha_j(T) = p(y_1,...,y_T,q_T=j)
α j ( T ) = p ( y 1 , ... , y T , q T = j )
因此,我们所求的 p ( y 1 , . . . , y T ) p(y_1,...,y_T) p ( y 1 , ... , y T ) q T q_T q T q T q_T q T
p ( y 1 , . . . , y T ) = ∑ j = 1 K α j ( T ) p(y_1,...,y_T) = \displaystyle{\sum_{j=1}^K \alpha_j(T)}
p ( y 1 , ... , y T ) = j = 1 ∑ K α j ( T )
上面这个推导过程,其实就是 HMM 的 Forward Algorithm(前向算法)
当然,有 forward 就有 backward,不过两者求出的概率是一样的
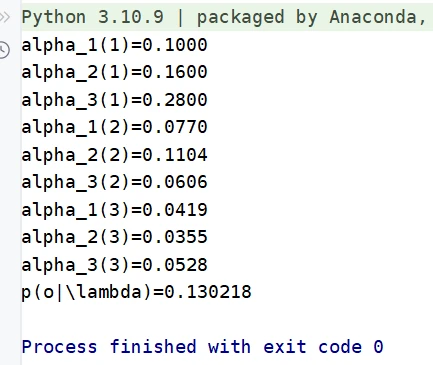
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import numpy as npdef forward (A, B, PI, observation, only_r = True ): """观测序列概率的前向算法""" n_state = len (A) T = len (observation) alpha = np.zeros((T, n_state)) for i in range (n_state): alpha[0 ][i] = PI[i] * B[i][observation[0 ]] for t in range (1 , T): for i in range (n_state): alpha[t][i] = np.dot(alpha[t-1 ], [a[i] for a in A]) * B[i][observation[t]] if not only_r: return alpha.tolist() return np.sum (alpha[len (alpha)-1 ])
后向算法
还是先定义后向概率
β i ( t ) = p ( y t + 1 , . . . , y T ∣ q t = i , λ ) \beta_i(t) = p(y_{t+1},...,y_T|q_t=i,\lambda)
β i ( t ) = p ( y t + 1 , ... , y T ∣ q t = i , λ )
β i ( t ) \beta_i(t) β i ( t ) λ \lambda λ q t q_t q t i i i
β i ( T − 1 ) = p ( y T ∣ q T − 1 = i ) = ∑ j = 1 K p ( y T , q T = j ∣ q T − 1 = i ) = ∑ j = 1 K p ( y T ∣ q T = j , q T − 1 = i ) ⋅ p ( q T = j ∣ q T − 1 = i ) = ∑ j = 1 K p ( y T ∣ q T = j ) ⋅ a i , j ⋅ β i ( T ) = ∑ j = 1 K b j ( y T ) ⋅ a i , j ⋅ β i ( T ) \begin{align}
\beta_i(T-1) &= p(y_T|q_{T-1}=i) \\
&= \displaystyle{ \sum_{j=1}^K p(y_T,q_T=j|q_{T-1}=i) } \\
&= \displaystyle{ \sum_{j=1}^K p(y_T|q_T=j,q_{T-1}=i) \cdot p(q_T=j|q_{T-1}=i) } \\
&= \displaystyle{ \sum_{j=1}^K p(y_T|q_T=j) } \cdot a_{i,j} \cdot \beta_i(T) \\
&= \displaystyle{ \sum_{j=1}^K b_j(y_T) } \cdot a_{i,j} \cdot \beta_i(T)
\end{align}
β i ( T − 1 ) = p ( y T ∣ q T − 1 = i ) = j = 1 ∑ K p ( y T , q T = j ∣ q T − 1 = i ) = j = 1 ∑ K p ( y T ∣ q T = j , q T − 1 = i ) ⋅ p ( q T = j ∣ q T − 1 = i ) = j = 1 ∑ K p ( y T ∣ q T = j ) ⋅ a i , j ⋅ β i ( T ) = j = 1 ∑ K b j ( y T ) ⋅ a i , j ⋅ β i ( T )
规定, β i ( T ) = 1 \beta_i(T) = 1 β i ( T ) = 1 P ( Y ∣ λ ) P(Y|\lambda) P ( Y ∣ λ )
β i ( 1 ) = p ( y 2 , . . . , y T ∣ q t = i ) P ( Y ∣ λ ) = p ( y 1 , . . . , y T ∣ λ ) = ∑ j = 1 K p ( y 1 , . . . , y T , q 1 = i ) = ∑ j = 1 K p ( y 1 , . . . , y T ∣ q 1 = i ) ⋅ p ( q 1 = i ) = ∑ j = 1 K p ( y 1 ∣ y 2 , . . . , y T , q 1 = i ) ⋅ p ( y 2 , . . . , y T ∣ q 1 = i ) ⋅ π i = ∑ j = 1 K p ( y 1 ∣ q 1 = i ) ⋅ β i ( 1 ) ⋅ π i = ∑ j = 1 K b i ( y 1 ) ⋅ β i ( 1 ) ⋅ π i \begin{align}
\beta_i(1) &= p(y_2,...,y_T|q_t=i) \\
P(Y|\lambda) &= p(y_1,...,y_T|\lambda) \\
&= \displaystyle{ \sum_{j=1}^K p(y_1,...,y_T,q_1=i) } \\
&= \displaystyle{ \sum_{j=1}^K p(y_1,...,y_T|q_1=i) \cdot p(q_1=i) } \\
&= \displaystyle{ \sum_{j=1}^K p(y_1|y_2,...,y_T,q_1=i) \cdot p(y_2,...,y_T|q_1=i) \cdot \pi_i } \\
&= \displaystyle{ \sum_{j=1}^K p(y_1|q_1=i) \cdot \beta_i(1) \cdot \pi_i } \\
&= \displaystyle{ \sum_{j=1}^K b_i(y_1) \cdot \beta_i(1) \cdot \pi_i }
\end{align}
β i ( 1 ) P ( Y ∣ λ ) = p ( y 2 , ... , y T ∣ q t = i ) = p ( y 1 , ... , y T ∣ λ ) = j = 1 ∑ K p ( y 1 , ... , y T , q 1 = i ) = j = 1 ∑ K p ( y 1 , ... , y T ∣ q 1 = i ) ⋅ p ( q 1 = i ) = j = 1 ∑ K p ( y 1 ∣ y 2 , ... , y T , q 1 = i ) ⋅ p ( y 2 , ... , y T ∣ q 1 = i ) ⋅ π i = j = 1 ∑ K p ( y 1 ∣ q 1 = i ) ⋅ β i ( 1 ) ⋅ π i = j = 1 ∑ K b i ( y 1 ) ⋅ β i ( 1 ) ⋅ π i
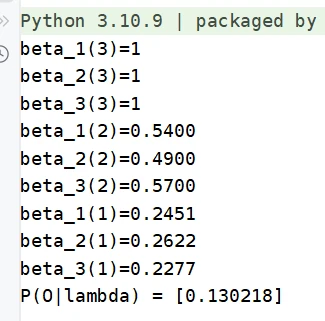
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def backward (A, B, PI, observation, only_r = True ): """观测序列概率的后向算法""" n_state = len (A) T = len (observation) beta = np.ones((T, n_state)) for t in range (len (observation) - 2 , -1 , -1 ): for i in range (n_state): beta[t][i] = np.dot( np.multiply(A[i], [b[observation[t+1 ]] for b in B]), beta[t+1 ] ) if not only_r: return beta.tolist() return np.dot( np.multiply(PI, [b[observation[0 ]] for b in B]), beta[0 ] )
两种算法结果一致
参考李航《统计学习方法》 https://github.com/sun2ot/python-study/blob/main/model/HMM.py
Baum-Welch 算法
假设我们只能获取观测序列 { O 1 , . . . , O T } \{O_1,...,O_T\} { O 1 , ... , O T } λ = ( A , B , π ) \lambda=(A,B,\pi) λ = ( A , B , π )
[!bug]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 def baum_welch (observation, n_state, max_iter=100 ): """Baum-Welch算法学习隐马尔可夫模型 :param observation: 观测序列 :param n_state: 可能的状态数 :param max_iter: 最大迭代次数 :return: A,B,π """ T = len (observation) n_observation = len (set (observation)) a = np.random.rand(n_state, n_state) a /= np.sum (a, axis=1 , keepdims=True ) b = np.random.rand(n_state, n_observation) b /= np.sum (b, axis=1 , keepdims=True ) p = np.random.rand(n_state) p /= np.sum (p) for _ in range (max_iter): alpha = forward(a,b,p,observation, only_r=False ) beta = backward(a,b,p,observation, only_r=False ) beta.reverse() gamma = [] for t in range (T): lst = np.zeros(n_state) for i in range (n_state): lst[i] = alpha[t][i] * beta[t][i] sum_ = np.sum (lst) lst /= sum_ gamma.append(lst) xi = [] for t in range (T - 1 ): sum_ = 0 lst = [[0.0 ] * n_state for _ in range (n_state)] for i in range (n_state): for j in range (n_state): lst[i][j] = alpha[t][i] * a[i][j] * b[j][observation[t + 1 ]] * beta[t + 1 ][j] sum_ += lst[i][j] for i in range (n_state): for j in range (n_state): lst[i][j] /= sum_ xi.append(lst) new_a = [[0.0 ] * n_state for _ in range (n_state)] for i in range (n_state): for j in range (n_state): numerator, denominator = 0 , 0 for t in range (T - 1 ): numerator += xi[t][i][j] denominator += gamma[t][i] new_a[i][j] = numerator / denominator new_b = [[0.0 ] * n_observation for _ in range (n_state)] for j in range (n_state): for k in range (n_observation): numerator, denominator = 0 , 0 for t in range (T): if observation[t] == k: numerator += gamma[t][j] denominator += gamma[t][j] new_b[j][k] = numerator / denominator new_p = [1 / n_state] * n_state for i in range (n_state): new_p[i] = gamma[0 ][i] a, b, p = new_a, new_b, new_p return a, b, p
测试数据如下
1 2 3 4 5 6 7 8 9 10 11 12 13 sequence = [0 , 1 , 1 , 0 , 0 , 1 ] A = [[0.0 , 1.0 , 0.0 , 0.0 ], [0.4 , 0.0 , 0.6 , 0.0 ], [0.0 , 0.4 , 0.0 , 0.6 ], [0.0 , 0.0 , 0.5 , 0.5 ]] B = [[0.5 , 0.5 ], [0.3 , 0.7 ], [0.6 , 0.4 ], [0.8 , 0.2 ]] PI = [0.25 , 0.25 , 0.25 , 0.25 ] alpha = forward(A, B, PI, sequence) print ("初始模型参数:" , alpha)A1,B1,P1 = baum_welch(sequence, 4 , max_iter=1000 ) alpha2 = forward(A1, B1, P1, sequence) print ("BN算法训练后:" , alpha2)

 微信
微信
