麻雀搜索算法
麻雀搜索算法
sparrow search algorithm
1 | XUE J, SHEN B. A novel swarm intelligence optimization approach: sparrow search algorithm[J]. Systems Science & Control Engineering, 2020, 8(1): 22-34. |
Abstract
[!quote] 受麻雀群体智慧、觅食和反捕食行为的启发,本文提出了一种新的群体优化方法,即麻雀搜索算法(SSA)。在19个基准函数上进行了实验,测试了SSA的性能,并将其与灰狼优化器(GWO)、引力搜索算法(GSA)和粒子群优化(PSO)等其他算法的性能进行了比较。仿真结果表明,所提出的SSA在精度、收敛速度、稳定性和鲁棒性方面优于GWO、PSO和GSA。最后,通过两个工程实例验证了所提出的SSA的有效性。
Introduction
- 受麻雀种群觅食和反捕食行为的启发,提出了一种新的SI技术,即SSA;
- 通过使用所提出的SSA,在一定程度上提高了优化搜索空间的探索和利用率;
- 所提出的SSA在两个实际工程问题中得到了成功的应用。
Biological characteristics
麻雀通常是群居鸟类,种类繁多。它们分布在世界大部分地区,喜欢生活在人类生活的地方。此外,它们是杂食性鸟类,主要以谷物或杂草的种子为食。众所周知,麻雀是常见的留鸟。与许多其他小鸟相比,麻雀非常聪明,记忆力也很强。请注意,有两种不同类型的圈养麻雀,既有生产者,也有觅食者。生产者积极寻找食物来源,而觅食者则由生产者获取食物。此外,有证据表明,鸟类通常灵活地使用行为策略,并在生产和觅食之间切换。也可以说,为了寻找食物,麻雀通常使用生产者和觅食者的策略。
研究表明,个体会监控群体中其他人的行为。同时,鸟群中的攻击者想要提高自己的捕食率,他们被用来与高摄入量的同伴争夺食物资源。此外,当麻雀选择不同的觅食策略时,个体的能量储备可能会发挥重要作用,而能量储备低的麻雀会觅食更多。值得一提的是,这些位于种群边缘的鸟类更容易受到捕食者的攻击,并不断试图获得更好的位置。位于中心的动物可能会向邻居靠近,以尽量减少其危险范围。我们也知道,所有的麻雀都表现出对一切事物好奇的本能,同时它们总是保持警惕。例如,当一只鸟确实探测到捕食者时,一个或多个个体发出啁啾声,整个群体就会飞走。
Mathematical model and algorithm
根据之前对麻雀的描述,我们可以建立数学模型来构建麻雀搜索算法。为了简单起见,我们将麻雀的以下行为理想化,并制定了相应的规则:
- 生产者通常拥有高水平的能量储备,并为所有觅食者提供觅食区域或方向。它负责确定可以找到丰富食物来源的地区。能量储备的水平取决于对个体适应度值的评估。
- 一旦麻雀发现捕食者,个体就会开始鸣叫,发出警报信号。当警报值大于安全阈值时,生产者需要将所有搜寻者带到安全区域。
- 只要寻找更好的食物来源,每只麻雀都可以成为生产者,但生产者和觅食者在整个种群中的比例没有变化。
- 能量较高的麻雀将充当生产者。为了获得更多的能量,一些饥饿的觅食者更有可能飞往其他地方觅食。
- 觅食者跟随能够提供最好食物的生产者寻找食物。与此同时,一些觅食者可能会不断监视生产者并争夺食物,以提高自己的捕食率。
- 处于群体边缘的麻雀在意识到危险时迅速向安全区域移动以获得更好的位置,而处于群体中间的麻雀则随机行走以靠近他人。
在模拟实验中,我们需要使用虚拟麻雀来寻找食物。麻雀的位置可以用以下矩阵表示:

其中 n 是麻雀的数量,d 表示要优化的变量的维度。那么,所有麻雀的适应度值可以用以下向量表示:
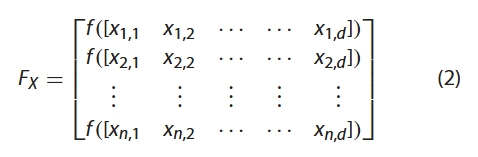
其中 n 表示麻雀的数量, 中每一行的值表示个体的适应度值。在SSA中,具有更好适应度值的生产者在搜索过程中优先获得食物。此外,因为生产者负责寻找食物和引导整个“鸟口”的流动。所以,生产者可以在比觅食者更广泛的地方寻找食物。根据规则(1)和(2),在每次迭代过程中,生产者的位置更新如下:

其中t表示当前迭代,表示迭代t时第i个麻雀的第j个维度的值。是迭代次数最多的常数。是一个随机数。和分别表示报警值和安全阈值。Q 是服从正态分布的随机数。L表示 的矩阵,其中内部的每个元素都是1。
当时,这意味着周围没有捕食者,组群会逐渐聚集,如下图。如果,则意味着一些麻雀已经发现了捕食者,所有麻雀都需要迅速飞往其他安全区域,即按正态分布随机移动到当前位置附近。
至于觅食者,他们需要执行规则(4)和(5)。如上所述,一些觅食者更频繁地监视生产者。一旦他们发现生产者找到了好的食物,他们就会立即离开目前的位置去争夺食物。如果他们赢了,他们可以立即获得生产者的食物,否则他们将继续执行规则(5)。觅食者的位置更新公式如下所述:
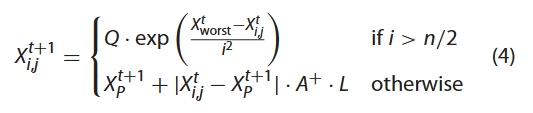
其中是生产者所占据的最佳位置。表示当前全局最差位置。A 表示一个 的矩阵,其中每个元素随机分配1或−1,。当时,这表明适应度值较差的第 i 个觅食者最有可能正在挨饿。
[!quote]
从公式可以看出,若i>n/2时,其值为一个标准正态分布随机数与一个以自然对数为底数的指数函数的积,当种群收敛时其取值符合标准正态分布随机数。 (其值会收敛于0)。若i<=n/2时,其取值为当前最优的麻雀的位置加上该麻雀与最优位置每一维距离随机加减后,将总和均分到每一维上。过程可以描述为在当前最优位置附近随机找一个位置,且每一维距最优位置的方差将会变得更小,即不会出现在某一维上与最优位置相差较大,而其他位置相差较小。(其值收敛于最优位置)。
[!tip]
在麻雀搜索算法中,觅食者是指除了生产者(producer)之外的其他麻雀。在觅食者位置更新的逻辑中,(i > n/2) 和 otherwise 分别对应了两种情况,表示了觅食者在更新位置时的不同策略:
当 (i > n/2) 时:这表示觅食者的编号 (i) 大于种群大小 (n) 的一半。在这种情况下,觅食者更倾向于向生产者靠近,以便更好地利用生产者的信息和种群中心的指引。因此,觅食者在更新位置时会采取更加向种群中心和生产者靠拢的策略,以加速搜索过程。
当 (i <= n/2) 时(即 otherwise):这表示觅食者的编号 (i) 小于等于种群大小 (n) 的一半。在这种情况下,觅食者可能更倾向于探索种群中的其他区域,而不是过于依赖生产者和种群中心的信息。因此,觅食者在更新位置时可能会更多地进行探索,以寻找潜在的更优解。
总体逻辑是,在麻雀搜索算法中,觅食者根据自身的编号与种群大小的关系,调整其更新位置的策略。这种策略旨在平衡利用生产者和种群中心的信息,同时保持一定的探索性,以更有效地搜索解空间中的潜在解。
侦查预警行为
在模拟实验中,我们假设这些意识到危险的麻雀占总种群的10%到20%。这些麻雀的初始位置是在种群中随机产生的。根据规则(6),该数学模型可以表示如下:
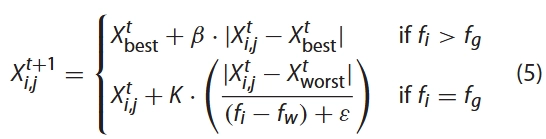
其中是当前的全局最优位置。是步长控制参数, 是一个平均值为0且方差为1的服从正态分布的随机数。是一个随机数。这里 是当前麻雀的适应度值。和分别是当前全局最佳和最差适应度值。是最小的常数,以避免零除法误差。
为了简单起见,当表示麻雀处于组的边缘时。代表种群中心的位置,在它周围是安全的。表明,处于种群中间的麻雀意识到了危险,需要靠近其他麻雀。表示麻雀移动的方向,也是步长控制参数。
[!tip] 关于 大小关系的含义
在麻雀搜索算法中,表示第只麻雀的适应度值,表示种群中适应度值最高的麻雀的适应度值。当某只麻雀的适应度值大于种群中适应度值最高的麻雀的适应度值时,这意味着该麻雀的适应度比整个种群中的其他麻雀都要高,因此该麻雀被认为处于种群的边缘,即在搜索空间中处于一个比较优越的位置,可能是一个局部最优解或者接近全局最优解。
当某只麻雀的适应度值等于种群中适应度值最高的麻雀的适应度值时,这表示该麻雀的适应度与整个种群中适应度最高的麻雀的适应度相同,即达到了种群的最高适应度水平。在这种情况下,可以理解为中心麻雀意识到了危险,因为虽然它的适应度与种群中最好的麻雀相同,但仍然可能存在更好的解决方案,因此需要继续搜索以寻找可能的更优解。
基于上述模型的理想化和可行性,SSA的基本步骤可以概括为算法1中所示的伪代码。

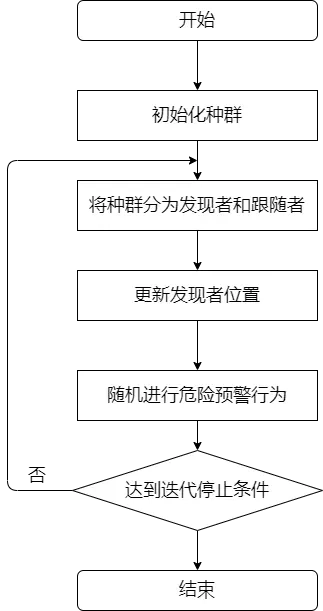
应用
1 | WANG J, HAO S, ZHAO G. CSSA-based collaborative optimization recommendation of users in mobile crowdsensing[J]. PEER-TO-PEER NETWORKING AND APPLICATIONS, 2023, 16(2): 803-817. |
Abstract
移动人群感知(MCS)作为一种新的感知范式,将人工智能与物联网相结合,利用具有智能设备(包括手机、智能汽车、可穿戴设备等)的移动用户来执行任务请求者请求的感知任务。移动用户固有的移动性使移动众感成为一个通用的平台,可以取代或补充现有的静态感知基础设施[1]。通过这种数据采集,MCS在交通监测[2]、环境现象观测[3]、移动医疗[4]等领域发挥着举足轻重的作用。传感系统由平台、任务发布者和参与者用户三部分组成。
任务发布者可以是一台机器,也可以是一个人。参与感测任务需要参与者的时间以及设备的感测、计算和通信资源。为了刺激广泛的用户参与,一些MCS系统为用户提交的有价值的传感器报告提供奖励[5]。激励可以采取不同的形式[6],包括金钱、通过游戏获得的娱乐或系统提供的服务。这些任务预算分配给根据传感数据花费的时间或提供的传感报告的质量完成传感任务的参与者[7]。因此,为了提高感知任务的数据质量[8,9]并降低任务成本[10-12],选择合适的用户是一个非常重要的先决条件。
移动人群感知系统通过用户参与任务,利用移动感知设备采集上传到平台的数据,完成数据采集。如何正确的用户,对于完成整个任务有着关键的影响。在之前的任务分配中,用户选择过程是通过分析用户属性与任务之间的匹配度来完成的。通常主要目标是提高感知数据的质量,用户选择基于可信用户选择[13]、质量推理方法[8]、用户信息质量分析[14]等方法。这些方法适用于收集单一数据类型的感知任务。当传感任务需要各种传感数据时,例如城市环境的数据收集,包括温度、湿度、图像和其他信息,并且用户设备上的传感器类型不同。与数据采集位置的距离不同,因此很难找到多个合适的用户来完成任务。
面对复杂的任务需求,仅考虑单个用户选择的优化很难满足需求。简单地增加具有相似属性的用户数量不仅会增加成本,还会造成数据冗余。因此,针对在这种复杂环境中寻找最优用户选择方案的问题[15],本文提出了一种新的感知任务用户选择框架——群感知麻雀搜索算法(CSSA)。分析了用户属性与任务之间的拟合程度,如图1所示。通过多个用户之间的协作,由他们自己的传感设备收集不同的数据,共同完成传感任务。为了解决复杂环境中的优化问题,智能优化算法中的麻雀搜索算法(SSA)[16]被用于解决该问题。该算法具有搜索精度高、收敛速度快、稳定性强的特点。
本文的贡献如下:
- 本文考虑了用户不同因素对任务的影响,提出了用户适应度的概念,通过计算用户的位置、设备状态和用户的历史信誉[17],分析了用户与任务的匹配程度、用户上传数据的质量可靠性,并根据对用户对任务优先级的分析,认为影响因素越全面,结论越可靠。
- 本文提出的方法是基于麻雀搜索算法。利用用户的适应度来划分用户的身份,然后通过混沌序列映射来初始化用户群体。模拟了麻雀搜索算法的迭代优化过程,求解了最优用户选择方案。与其他群智能优化算法相比,它具有优化能力强、收敛速度快的优点。
- 基于任务所需的不同类型的感知数据,采用了多用户协作的方法。每个用户使用当前设备的传感器收集传感数据,然后将多个用户上传的信息进行整合,完成传感任务。与非合作用户相比,结果数据质量更高。
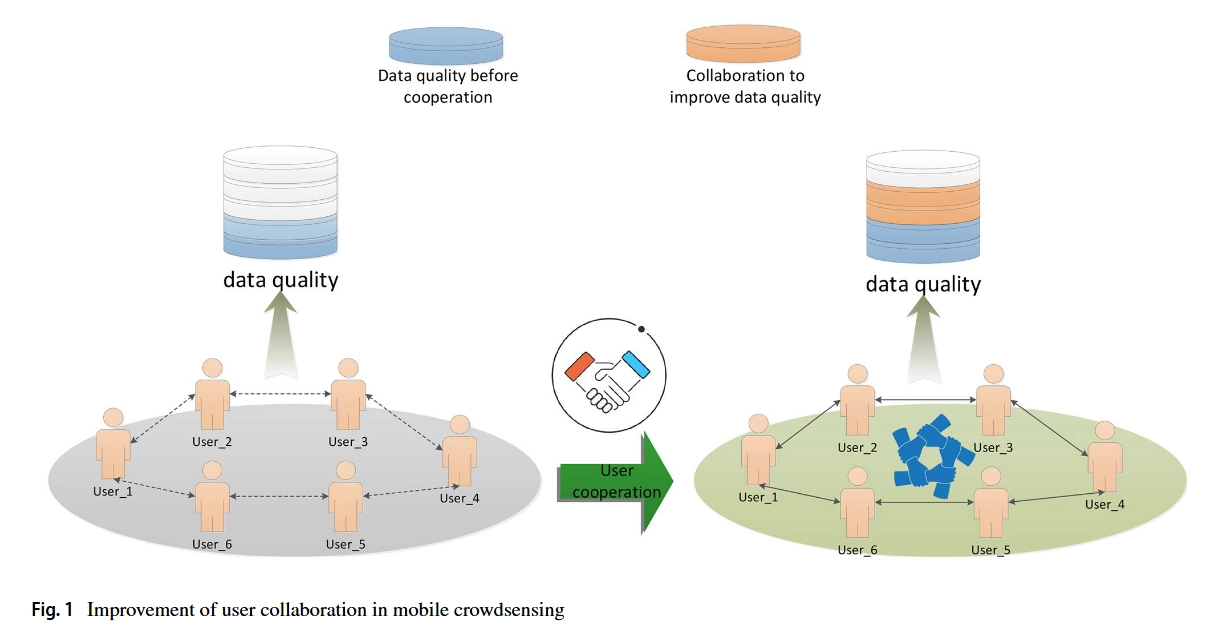
Related work
任务分配是MCS的一个主要研究方向。它收集来自移动用户的感知数据,并获得感知结果以完成任务。一般来说,影响任务质量的因素有很多,包括数据收集量、任务持续时间和任务空间-时间覆盖率[18]。收集的传感器数据越多,任务的质量就越高。适当的任务空间-时间覆盖通常也意味着更高的任务质量。影响任务成本的因素还有很多[19],包括用户招募成本、用户移动成本和数据传输成本。
本文的用户推荐方法综合考虑了以上三个方面。用户的信息分为位置、权力、信誉等,通过多方面的信息综合考虑用户,确保任务的数据质量。并通过用户设备传感器类型和任务匹配程度来满足任务数据类型的各种需求。与以前的任务分配方法相比,CSSA方法更适合于需要多种数据类型的复杂情况。此外,根据群体智能优化算法。
Problem description
由于现有的研究方法侧重于单一类型的感知数据收集,在面对复杂的任务要求时效果并不理想。而且,面对复杂的任务需求,仅考虑单个用户选择的优化很难满足需求。简单地增加具有相似属性的用户数量,不仅会增加任务成本,还会造成数据冗余。
为了解决这个问题,本文提出了一个用户选择框架,该框架综合考虑了各种用户属性对任务感知数据质量的影响以及多用户协作问题。该策略的目标是在确保任务成本的同时提高感知数据的质量,同时考虑用户选择的时间。本文将用户对任务的影响因素主要归结为以下几个方面:用户与数据采集地点的距离;用户设备的传感器类型与任务所需的感测数据类型之间的一致程度;感测装置的剩余功率;基于历史数据的用户信誉。
由于待解决问题的复杂性很高,针对上述影响因素提出了适合度的概念,并以适合度值作为衡量用户优先级和匹配度的参考。适合度计算所需的信息包括用户通过定位的位置信息、用户设备上传的设备剩余电量和传感器类型信息,以及基于用户历史任务完成记录获得的信誉信息。通过对这些值的计算,完成了对采集到的任务数据的质量控制,分析用户是否适合当前任务。这些适应度值是智能优化算法的重要参考标准,如图2所示。
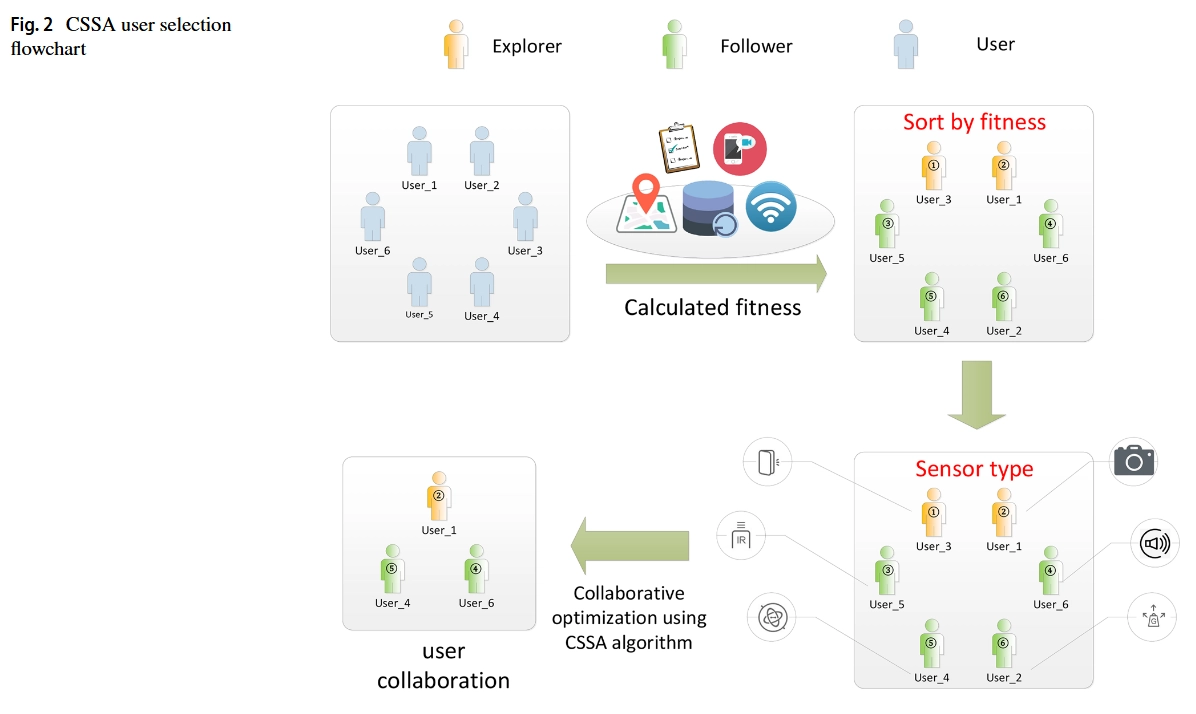
移动众感知平台由许多感知用户组成。U表示任务发布时可以参与系统的用户集合, 表示当前所有用户对该任务的适应度值,用户集为 的顺序。按比例将用户分为探索者(初级传感数据采集任务适应度高)和跟随者(适应度低,负责补充数据和改进传感数据类型),并分别根据不同的职责进行任务感知。最后,根据CSSA算法筛选出合适的感知用户。
基于上述用户选择模型,在考虑数据质量、任务成本和分配时间的前提下,将数据质量最大化的用户选择问题定义如下:
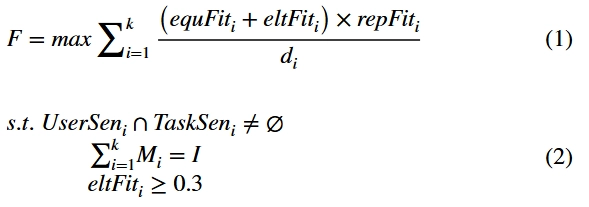
其中 是的全1矩阵,用于控制所有用户传感器类型的总和以满足任务所需的类型,其中是任务所需类型的数量。是用户和任务感知位置之间的距离,通过选择靠近用户的位置,从而降低成本。确保用户的设备类型满足至少一个任务要求。目标函数V是表示用户通过设备的剩余功率和设备的适合度来完成任务的数据质量,然后通过乘以信誉适合度来表示最终的完成效果。
同时,为了提高用户选择效率和数据质量,本文采用参与者协作的方式来完成任务。分析当前任务所需的数据类型,并要求用户根据不同的传感器完成他们可以提供的信息类型。然后,平台对多个用户上传的内容进行汇总分析,完成传感数据的采集。该算法利用了群体间协作的特点,有利于移动众感知中参与者和用户群体的协作,完成感知任务。同时,综合分析感知用户与用户的位置、设备等多个属性的匹配程度。在众感中,通过分析多种影响因素的用户选择策略和用户之间的合作,可以提高感知数据的质量和任务分配时间,并显著提高众感平台的性能。表1总结了本文中使用的重要符号。
User collaborative recommendation method
Calculation of user fitness value
Position fitness
通过计算任务位置与用户的匹配关系,当用户远离任务时,用户需要移动的距离会增加,从而增加任务完成时间和更高的任务成本。鉴于这种情况,本文引入了位置适合度的概念,并将用户和任务之间的距离作为衡量适合度的指标进行了比较。计算公式如下:
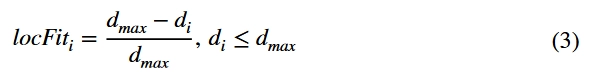
其中是所有用户与任务之间的最大距离,是用户与任务之间距离。根据公式(1)的计算,用户与任务之间的距离越小,位置适应度越大;当用户和任务之间的距离变长时,适合度逐渐降低。当适应度等于1时,它达到最大值,这意味着用户接近任务。从位置的角度来看,用户具有最高的优先级。上述公式将用户与任务之间的位置关系转换为距离,其中欧几里德距离用于计算用户ui与任务s之间的距离,用户的位置为(xi,yi),任务的位置为为(x,y),公式如下:
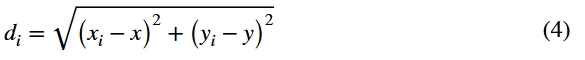
原来路径任务在用户感知区域时,随着任务之间的距离越来越近,用户与任务之间的适应度位置也会提高,用户想要执行的任务意图越来越大。因此用户可以主动加快速度,减少移动时间,降低任务完成的速度,提高整体效率。
Electric quantity fitness
电量适合度被认为是移动设备的剩余电量,因为在完成任务的过程中,传感器的感知数据需要不断利用,感知数据需要通过通信网络实时上传到平台。这个过程需要不断消耗移动设备的电量。因此,电量适合度也是一个重要的考虑参数,它决定了移动设备是否有能力完成感知数据收集。当电量较低时(根据调查,当设备电池电量低于30%时,用户参与任务的意愿非常低,因此本文将电量设置为30%),用户很可能不愿意参与任务。电量适应度的计算根据电量剩余百分比[0,1]中的数据表示,公式如下:

其中和分别表示当前用户的设备的剩余可用功率和总功率。
Equipment fitness
根据任务需要感知的数据类型不同,对感知用户设备的要求也不同。因此,需要考虑候选参与者的传感设备上所需传感器的可用性,这将显著影响数据的可靠性和传感结果的质量。在不同要求的传感任务中,每个人的设备都必须配备所有必要的传感器,当一些必要的传感器缺失时,平台会认为这些用户没有资格选择。本文列出了一些可能的传感器,如表2所示。然而,由于用户2的信号质量较低,数据上传过程可能不稳定,从而影响任务的数据质量。因此,采用用户合作的方法,由多个用户收集不同类型的数据,并合作完成感知任务。例如,用户3和用户5分别具有位置传感器和温度传感器,并且具有更高的信息质量,因此可以通过用户之间的合作更好地完成感知任务。为了量化匹配程度,使用设备适应度来表示用户和任务之间的硬件能力匹配程度,并将任务依次分配给最好的用户,这不仅可以降低任务所需的成本,还可以提高数据质量。设备信息与传感内容的匹配程度如图3所示。
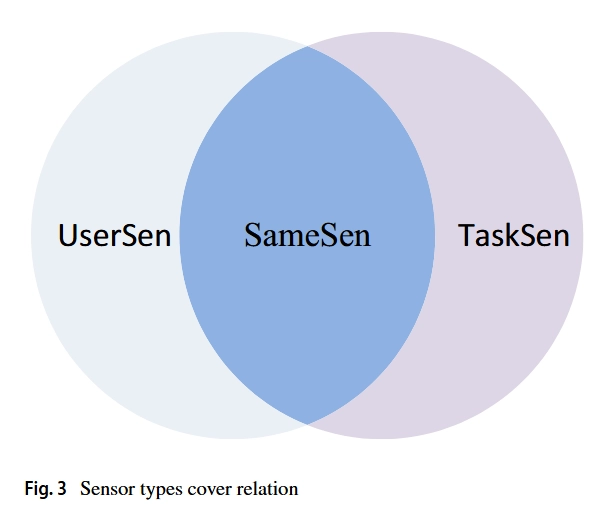
其中是传感器重组集,表示用户设备的传感器类型集与任务感知内容集的重叠部分。其中一些是必不可少的传感器,其他非关键类型的传感器越来越好,因此传感器的符合度为:
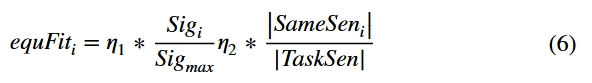
其中和分别表示设备当前信号质量和最高信号质量,并以分数的方式分析用户当前信号质量强度。和的比值表示当前设备类型与任务需求类型之间的拟合程度。是信号强度系数,是传感器符合度系数,两者之间的关系为,控制着不同变量的权重。
然而,每个感知用户不需要拥有所需的所有感知传感器类型,而是可以通过多个用户之间的合作来完成多种类型感知数据的收集。如上所述,用户3和5一起工作以获得比单独的用户2更好的结果。因此,1×j的矩阵Mi用于记录当前用户i的传感器类型,j是任务所需的传感器类型。用户携带的设备所拥有的传感器类型设置为1,如果没有传感器,则设置为0。
Reputation fitness
由于声誉本身很难直接评估,因此用户的声誉[38]是基于他们之前参与感知任务来评估的。评估标准包括他们是否致力于完成分配给他们的任务以及完成这些任务的能力。以下公式(7)和(8)分别用于评估每个参与者的信誉参数:

其中Spti表示用户参与的任务集,Cti表示用户被选择的任务集;比率Cti表示用户将参与该任务的概率;Scti表示用户完成的一组任务,Fti表示由用户完成的任务集,比率Scti表示用户完成任务的概率。由于这两个参数相对不同,因此使用它们的集合平均值来给出参与者的总体声誉。因此,每个用户的个人信誉适合度由以下公式计算:

因此,根据上述方法,每个用户的适应度计算如下:
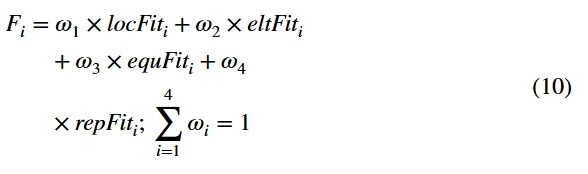
根据感测服务的性质,可以给予某个参数比其他参数更高的权重。
Selection of sensing users
当感知任务发布时,愿意参与任务的感知用户向平台报告,参与者集为U=(u1,u2,u3…un)。平台首先根据用户属性和历史数据,通过公式(8)计算出每个用户的(信誉?)适应度 Fi。
初始化所有用户在优化算法中的位置。为了提高算法的全局搜索能力,避免迭代后期种群多样性的降低,采用逻辑混沌映射代替随机数生成,使位置更加随机、规则。公式如下:
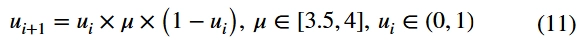
其中μ是Logistic参数,当μ的值满足3.5699456<μ<=4的条件时,迭代生成的值处于伪随机分布状态。通过上述公式的迭代计算,n个参与者在维度d下的位置由矩阵表示:
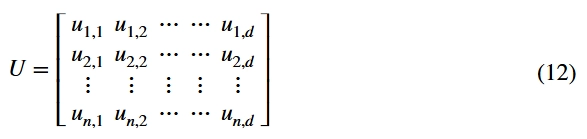
参与者的适应度值可以表示为:
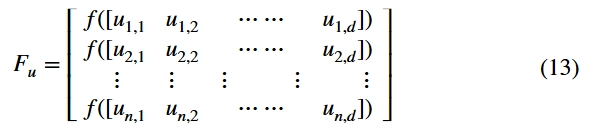
其中n表示参与者的数量,d表示优化变量的维度。通过计算上述矩阵,按适合度值对用户进行排序,并通过设置值将用户划分为探索者和追随者的两种不同身份,表示探索者占所有参与者的比例。当前用户由数组 ID[n]标识,0表示follower,1表示explorer。其中,探索者由于任务适应度高,负责主要的传感数据采集,是传感任务的主要成分。追随者与探索者的身份相对应。
由于适应度低,追随者跟随探索者收集数据,并负责补充数据和改进传感数据类型。例如,当Pr设置为0.2时,探索者与跟随者的比例为2:8。探索者的位置更新如下:
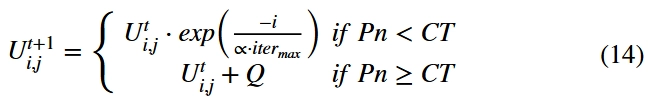
其中t表示当前迭代次数,表示当前维度,表示迭代t时第i个感知用户的第j个维度的位置,是迭代次数最多的常数。是一个随机数,和分别表示子区域的任务完成度和完成阈值。Q是遵循正态分布的随机数。
当 时,表示当前区域的任务完成次数未达到阈值,当前搜索者可以继续完成子区域的任务。当使用时,意味着当前区域的参与者数量满足任务完成的要求,所有探索者都需要完成其他子区域的感知任务。
跟随者跟随在探索者附近,负责部分传感数据的收集,随着探索者完成任务,两者的适应度值会动态变化,当跟随者发现探索者的适应度低于自己时,他们会产生竞争关系,两者的身份也会发生变化,当前用户ID[i]的值也会发生反转。职位更新公式如下:
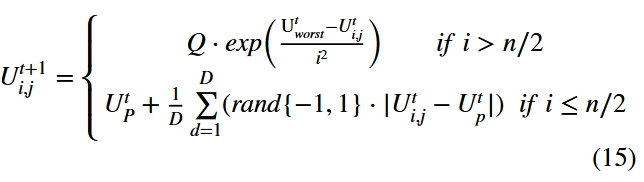
其中是探索者最佳位置,是全局最差的位置。D表示维度值。当跟随者的适应度值合适时,移动到当前探险家的位置附近,随机到最佳位置附近的位置,距离最佳位置的每个维度的方差变小;当 时,这表明跟随者在当前感知用户队列中的适应度值非常低,无法完成当前任务,然后在其他区域中寻找感知任务。
此外,所有任务参与者中的一部分被选为监控器,这些监控器在人群中随机生成,负责防止用户集中在最佳感知位置并陷入局部最优。选择10%~20%的感应用户作为监视器,其位置表达式更新如下:
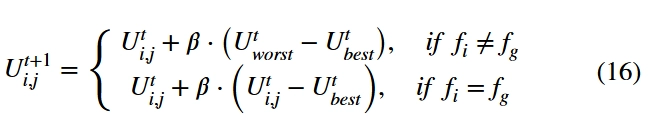
其中和分别表示当前全局最优位置和最差位置;作为步长控制参数,是一个平均值为0、方差为1的正态分布随机数;是当前个体用户的适应度值;是当前的全局最优适应度值。为了避免陷入局部最优,如果用户处于最佳位置,他应该逃到最佳位置和最差位置之间的随机位置;否则,他应该逃到他自己和随机位置之间的随机位置。
优化算法的目的是找到目标函数的最大值,即找到最符合任务要求的用户,从而提高数据质量。
Experimental results and analysis
模拟实验的数据来自Geolife[39]数据集,该数据集包含182个用户的GPS轨迹,由一系列时间戳表示。每个点包含经度、纬度和高度的坐标信息,包括17621个轨迹。本文主要使用经纬度坐标信息。传感器的可用类别由用户携带,剩余功率等随机分配给用户。
为了使实验结论更加可靠,本文还使用真实的数据集进行验证,通过众包平台“猪八戒”上的数据采集工具进行抓取,筛选出交易记录最多的前200名用户。每个传感用户的信息包括位置、价格、历史完工数据和其他信息。本文使用的仿真工具是MATLAB,它是在Windows10的64位平台上实现的。处理器为AMD R7-4800 h,主频为2.9 GHz,内存为16.00 GB。
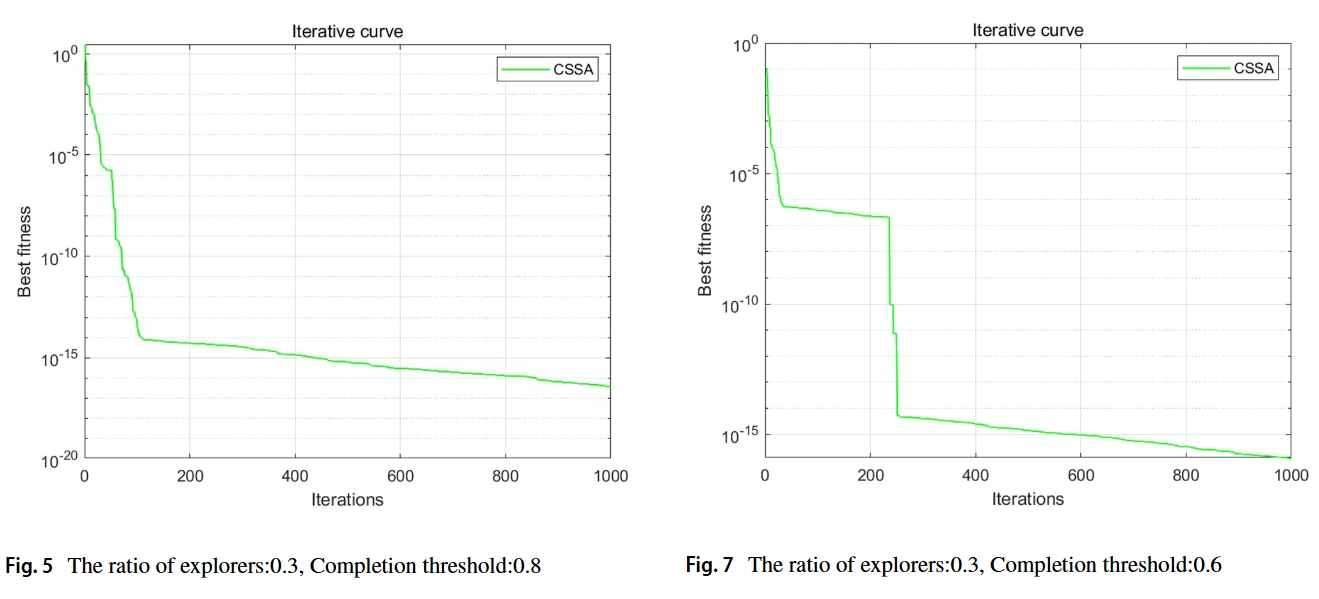
在本文中,首先使用测试函数来调整算法。调整ED和CT两个参数以优化算法的优化性能,并通过1000次迭代获得最快的迭代率。如图4、5、6和7所示,区域完成度阈值设置为0.8,迭代次数设置为1000,以调试探索者和跟随者的比例。图4和图5中探索者和追随者的比例分别为0.2:0.8和0.3:0.7。当任务中探索者的比例增加时,迭代速度略慢,但在有限的迭代次数中,适应度值的准确性显著提高。因此,适当增加探索者在参与者群体中的比例有利于提高算法的性能。
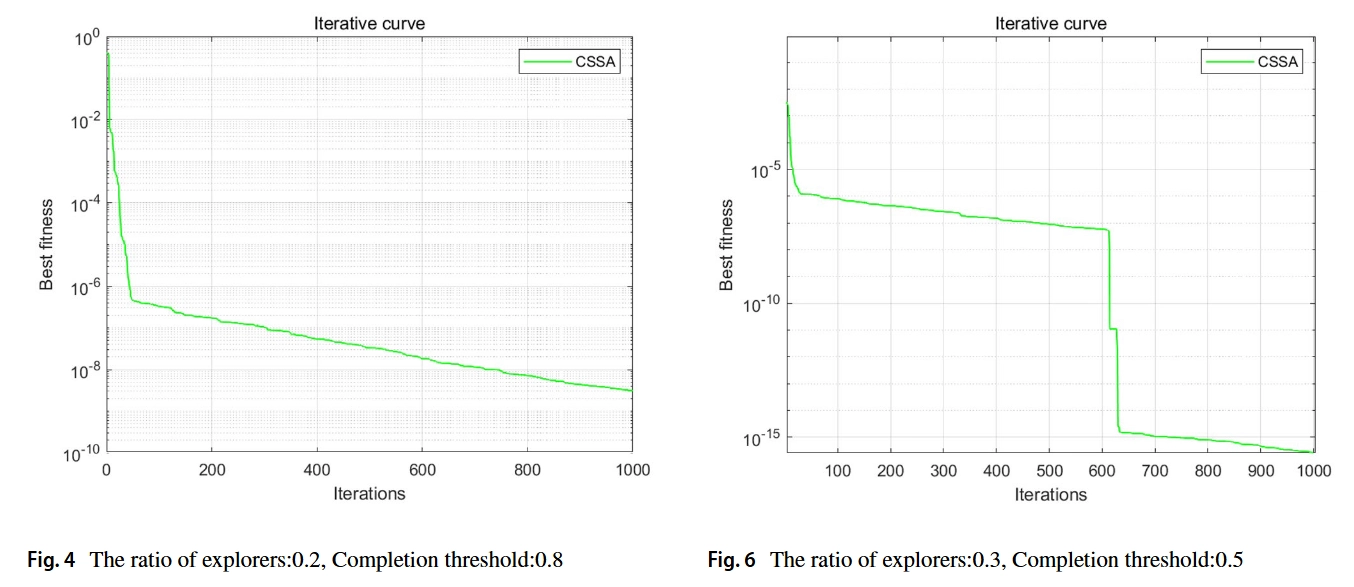
当探索者和跟随者的数量之比固定为0.3:0.7时,设置区域完成阈值,如图6和图7所示。在完成阈值降低后,迭代曲线在快速下降后将呈现出明显的平坦期。由于任务完成设置的程度降低,参与者可能会重复改变感知区域,导致适应度准确性在一段时间内几乎没有提高,从而降低任务完成效率。图6和图7中转换曲线的比较表明,完成阈值设置得越低,曲线的平坦化周期就越长。经过反复测试,发现0.8的完成阈值CT表现最好。因此,ED参数设置为0.3,CT参数设置为0.8。
 微信
微信- 支付宝

