随机梯度下降法 SGD
stochastic gradient descent
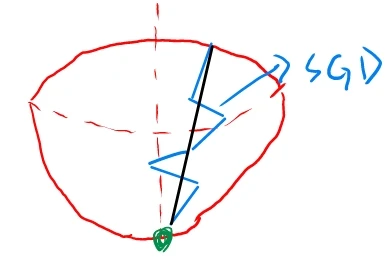
假设红色部分为一个下凹空间,现在要前往空间的最低点。随机梯度下降法 SGD 低效的根本问题在于,每一步虽然都是立足于当前点的梯度方向(蓝线 ),但梯度的方向并不一定指向最小值的方向(黑线 )。
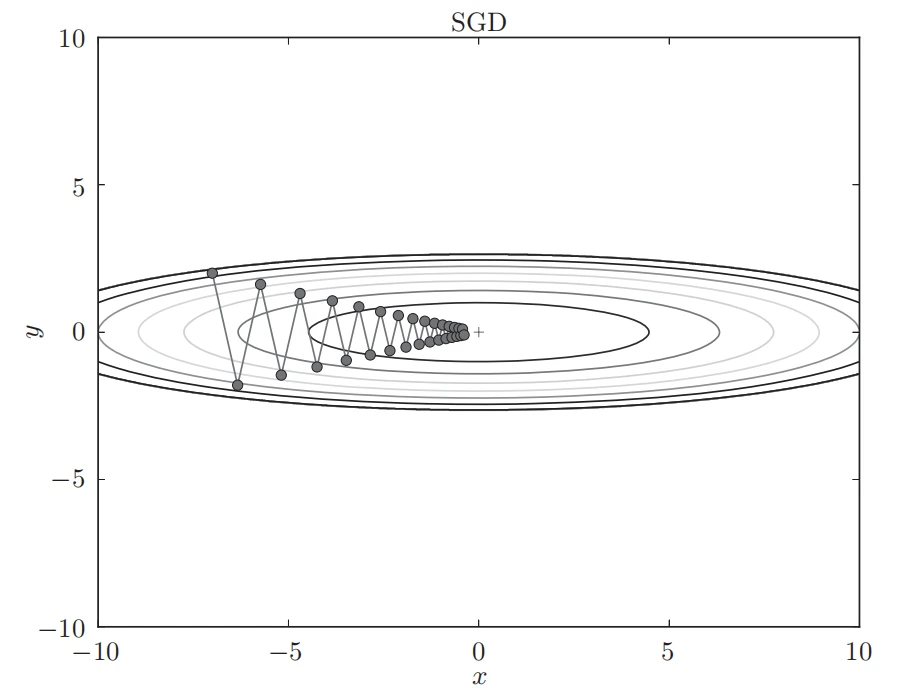
基于SGD的最优化的更新路径:呈“之”字形朝最小值(0, 0)移动,效率低
1 2 3 4 5 6 7 8 9 10 class SGD : """随机梯度下降法(Stochastic Gradient Descent)""" def __init__ (self, lr=0.01 ): self .lr = lr def update (self, params, grads ): for key in params.keys(): params[key] -= self .lr * grads[key]
Momentum
数学式表示
v ← α v − η ∂ L ∂ W W ← W + v \begin{align}
v & \leftarrow \alpha v - \eta \frac{\partial L}{\partial W} \\
W & \leftarrow W + v
\end{align}
v W ← αv − η ∂ W ∂ L ← W + v
W W W ∂ L ∂ W \frac{\partial L}{\partial W} ∂ W ∂ L W W W η \eta η v v v
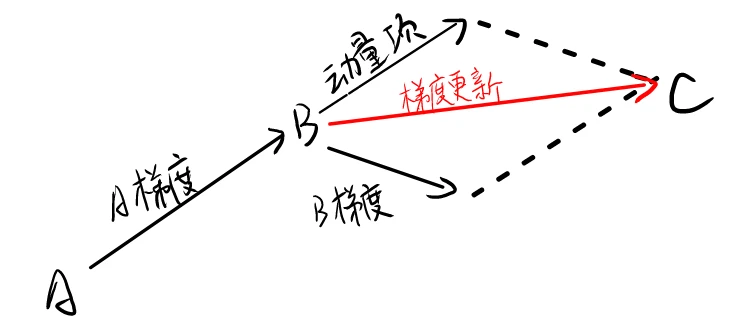
当从 A 点沿梯度方向走到 B 点时,将 B 的梯度方向与动量项合并,作为新的更新方向
如果 B 点梯度方向不变,由于加上了动量项,可以使 SGD 加快更新
如果 B 点梯度方向改变,动量项可以减弱更新幅度,防止发生较大改变导致更新不稳定
基于 Momentum 的最优化的更新路径
和 SGD 相比,我们发现“之”字形的“程度”减轻了。这是因为虽然 x 轴方向上受到的力非常小,但是一直在同一方向上受力 ,所以朝同一个方向会有一定的加速。
反过来,虽然 y 轴方向上受到的力很大,但是因为交互地受到正方向和反方向的力,它们会互相抵消 ,所以 y 轴方向上的速度不稳定。因此,和 SGD 时的情形相比,可以更快地朝 x 轴方向靠近,减弱“之”字形的变动程度。
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Momentum : """Momentum SGD""" def __init__ (self, lr=0.01 , momentum=0.9 ): self .lr = lr self .momentum = momentum self .v = None def update (self, params, grads ): if self .v is None : self .v = {} for key, val in params.items(): self .v[key] = np.zeros_like(val) for key in params.keys(): self .v[key] = self .momentum*self .v[key] - self .lr*grads[key] params[key] += self .v[key]
AdaGrad
自适应地为各个维度的参数分配不同的学习率
在神经网络的学习中,学习率过小,会导致学习花费过多时间;反过来,学习率过大,则会导致学习发散而不能正确进行。
在关于学习率的有效技巧中,有一种被称为学习率衰减 (learning rate decay)的方法,即随着学习的进行,使学习率逐渐减小。AdaGrad(Ada 意为 Adaptive)会为参数的每个元素适当地调整学习率,与此同时进行学习。
h ← h + ∂ L ∂ W ⊙ ∂ L ∂ W W ← W − η 1 h + ϵ ∂ L ∂ W \begin{align}
h & \leftarrow h + \frac{\partial L}{\partial W} \odot \frac{\partial L}{\partial W} \\
W & \leftarrow W - \eta \frac1{\sqrt{h+\epsilon}} \frac{\partial L}{\partial W}
\end{align}
h W ← h + ∂ W ∂ L ⊙ ∂ W ∂ L ← W − η h + ϵ 1 ∂ W ∂ L
h h h ⊙ \odot ⊙ ϵ \epsilon ϵ
优点:h 较小时,可以放大梯度;较大时,可以约束梯度(奖励+惩罚)
缺点:
梯度累积导致学习率单调递减,后期学习率极小
仍然需要设置一个合适的全局初始学习率
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class AdaGrad : """AdaGrad""" def __init__ (self, lr=0.01 ): self .lr = lr self .h = None def update (self, params, grads ): if self .h is None : self .h = {} for key, val in params.items(): self .h[key] = np.zeros_like(val) for key in params.keys(): self .h[key] += grads[key] * grads[key] params[key] -= self .lr * grads[key] / (np.sqrt(self .h[key]) + 1e-7 )
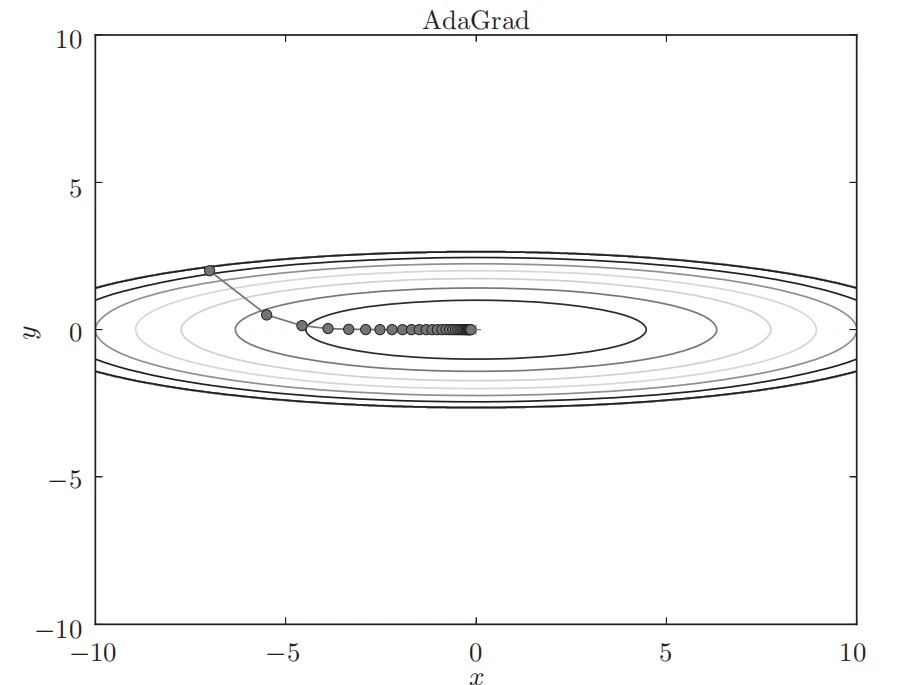
基于 AdaGrad 的最优化的更新路径
RMSProp
在 AdaGrad 基础上产生的改进版
G t = β G t − 1 + ( 1 − β ) g t 2 △ θ t = − η G t + ϵ g t \begin{align}
G_t = \textcolor{red}{\beta} G_{t-1} + \textcolor{red}{ (1-\beta) } g_t^2 \\
\vartriangle \theta_t = - \frac \eta {G_t + \epsilon} g_t
\end{align}
G t = β G t − 1 + ( 1 − β ) g t 2 △ θ t = − G t + ϵ η g t
其中, β \beta β
可以看见,RMSProp 与 AdaGrad 不同,它通过增加一个衰减系数 ,只关注最近某一时间窗口内的下降梯度,来控制历史梯度信息的获取。
G t G_t G t β \beta β
当 β \beta β
当 β \beta β
因此可以在一定程度上缓解 AdaGrad 在后期学习率太小这个问题。
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class RMSprop : def __init__ (self, lr=0.01 , decay_rate = 0.99 ): self .lr = lr self .decay_rate = decay_rate self .h = None def update (self, params, grads ): if self .h is None : self .h = {} for key, val in params.items(): self .h[key] = np.zeros_like(val) for key in params.keys(): self .h[key] *= self .decay_rate self .h[key] += (1 - self .decay_rate) * grads[key] * grads[key] params[key] -= self .lr * grads[key] / (np.sqrt(self .h[key]) + 1e-7 )
Adam
Momentum + RMSProp = Adam
Adam 采用两个不同的超参数 β1 和 β2 来控制动量以及 RMSProp 中指数加权移动平均 s t s_t s t
m t = β 1 ⋅ m t − 1 + ( 1 − β 1 ) ⋅ g t v t = β 2 ⋅ v t − 1 + ( 1 − β 2 ) ⋅ ( g t ⊙ g t ) θ t = θ t − 1 − η ⋅ m t ^ v t ^ + ϵ \begin{align}
m_t & = β_1 · m_{t-1} + (1 - β_1) · g_t \\
v_t & = β_2 · v_{t-1} + (1 - β_2) · (g_t⊙g_t) \\
\theta_t & = \theta_{t-1} - \frac {\eta \cdot \hat{m_t}} { \sqrt{\hat{v_t}} + \epsilon}
\end{align}
m t v t θ t = β 1 ⋅ m t − 1 + ( 1 − β 1 ) ⋅ g t = β 2 ⋅ v t − 1 + ( 1 − β 2 ) ⋅ ( g t ⊙ g t ) = θ t − 1 − v t ^ + ϵ η ⋅ m t ^
通常,β1=0.9,β2=0.999,ϵ=1e−7
初始化偏差修正
Adam 的一个改进点是 Adam 对一阶矩估计和二阶矩估计进行了修正,使其近似为对期望的无偏估计 。修正方式为:
m t ^ = m t 1 − β 1 t v t ^ = v t 1 − β 2 t \begin{align}
\hat{m_t} = \frac {m_t} {1-\beta_1^t} \\
\hat{v_t} = \frac {v_t} {1-\beta_2^t}
\end{align}
m t ^ = 1 − β 1 t m t v t ^ = 1 − β 2 t v t
下面对偏差修正进行解释。
通过下列推导得到在前面所有时间步上只包含梯度和衰减率的函数 ,即消去 v:
E (aX) = aE (X),好像是有这么个期望公式?概率论忘干净了 hhhh
可以发现,当 t 取的很小时,例如 t=1,此时 v 1 = 0.001 g 1 2 v_1 = 0.001g_1^2 v 1 = 0.001 g 1 2 v t ^ = v t 1 − β 2 t \hat{v_t} = \frac {v_t} {1-\beta_2^t} v t ^ = 1 − β 2 t v t v t ^ ≈ v t \hat{v_t} \approx v_t v t ^ ≈ v t
对一阶动量的修正也是同理
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Adam : """Adam (http://arxiv.org/abs/1412.6980v8)""" def __init__ (self, lr=0.001 , beta1=0.9 , beta2=0.999 ): self .lr = lr self .beta1 = beta1 self .beta2 = beta2 self .iter = 0 self .m = None self .v = None def update (self, params, grads ): if self .m is None : self .m, self .v = {}, {} for key, val in params.items(): self .m[key] = np.zeros_like(val) self .v[key] = np.zeros_like(val) self .iter += 1 lr_t = self .lr * np.sqrt(1.0 - self .beta2**self .iter ) / (1.0 - self .beta1**self .iter ) for key in params.keys(): self .m[key] = self .beta1*self .m[key] + (1 -self .beta1)*grads[key] self .v[key] = self .beta2*self .v[key] + (1 -self .beta2)*(grads[key]**2 ) params[key] -= lr_t * self .m[key] / (np.sqrt(self .v[key]) + 1e-7 )
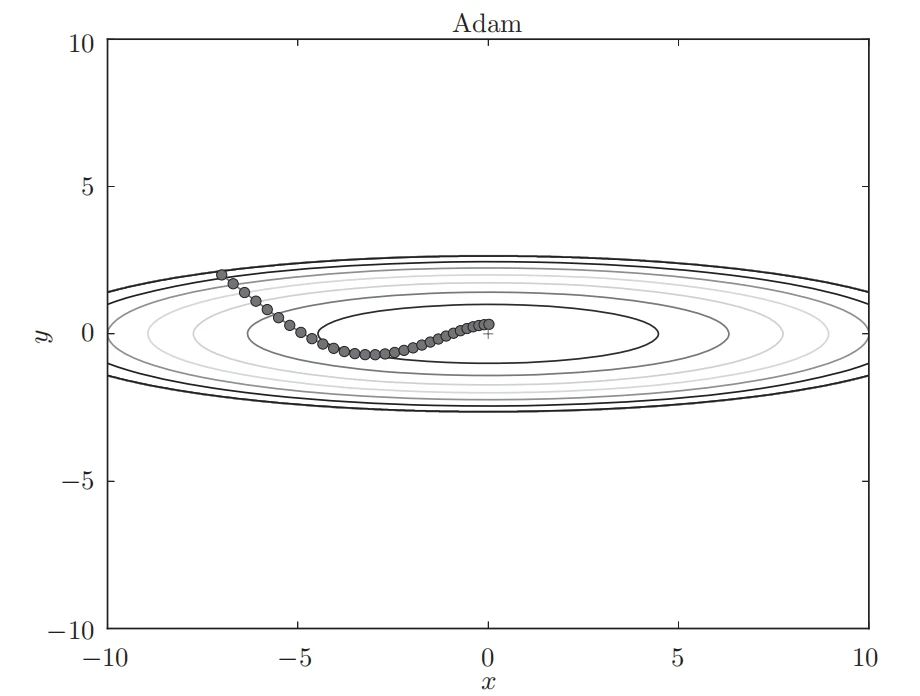
基于 Adam 的最优化的更新路径
虽然 Momentun 也有类似的移动,但是相比之下,Adam 的 y 轴震荡程度有所减轻,这得益于学习的更新程度被适当地调整了。
对比
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import matplotlib.pyplot as pltfrom d2l.mnist import load_mnistfrom d2l.common.util import smooth_curvefrom d2l.common.multi_layer_net import MultiLayerNetfrom d2l.common.optimizer import *(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True ) train_size = x_train.shape[0 ] batch_size = 128 max_iterations = 2000 optimizers = {} optimizers['SGD' ] = SGD() optimizers['Momentum' ] = Momentum() optimizers['AdaGrad' ] = AdaGrad() optimizers['Adam' ] = Adam() networks = {} train_loss = {} for key in optimizers.keys(): networks[key] = MultiLayerNet( input_size=784 , hidden_size_list=[100 , 100 , 100 , 100 ], output_size=10 ) train_loss[key] = [] for i in range (max_iterations): batch_mask = np.random.choice(train_size, batch_size) x_batch = x_train[batch_mask] t_batch = t_train[batch_mask] for key in optimizers.keys(): grads = networks[key].gradient(x_batch, t_batch) optimizers[key].update(networks[key].params, grads) loss = networks[key].loss(x_batch, t_batch) train_loss[key].append(loss) if i % 100 == 0 : print ( "===========" + "iteration:" + str (i) + "===========" ) for key in optimizers.keys(): loss = networks[key].loss(x_batch, t_batch) print (key + ":" + str (loss)) markers = {"SGD" : "o" , "Momentum" : "x" , "AdaGrad" : "s" , "Adam" : "D" } x = np.arange(max_iterations) for key in optimizers.keys(): plt.plot(x, smooth_curve(train_loss[key]), marker=markers[key], markevery=100 , label=key) plt.xlabel("iterations" ) plt.ylabel("loss" ) plt.ylim(0 , 1 ) plt.legend() plt.show()
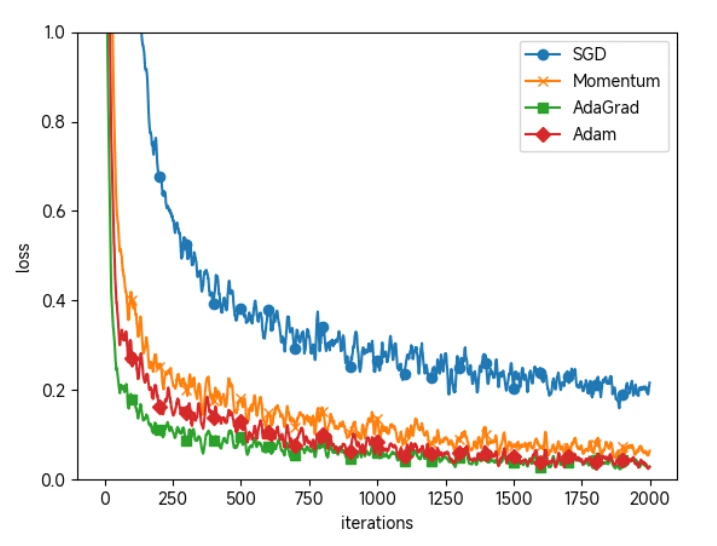
基于 MNIST 数据集的4种更新方法的比较:横轴表示学习的迭代次数(iteration),纵轴表示损失函数的值(loss)
权重的初始值
初始权重可以为 0 吗
将权重初始值设为 0 的话,将无法正确进行学习。严格地说,不能将权重初始值设成一样的值 。因为在误差反向传播法中,所有的权重值都会进行相同的更新,因此,权重被更新为相同的值,并拥有了对称的值(重复的值)。
这使得神经网络拥有许多不同的权重的意义丧失了。为了防止“权重均一化”(严格地讲,是为了瓦解权重的对称结构 ),必须随机生成初始值。
隐藏层的激活值分布
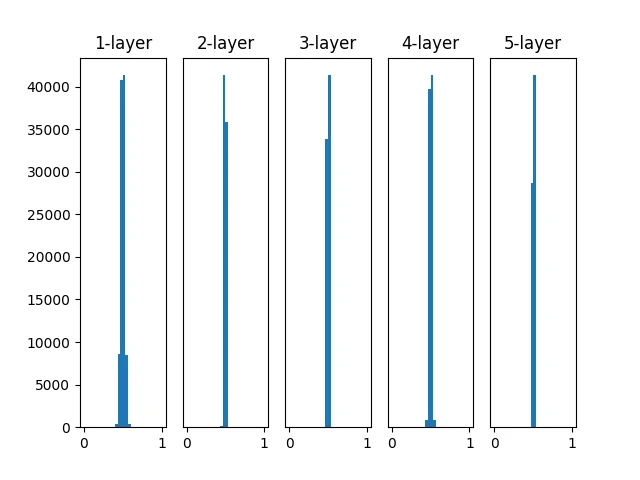
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import numpy as npimport matplotlib.pyplot as pltdef sigmoid (x ): return 1 / (1 + np.exp(-x)) def ReLU (x ): return np.maximum(0 , x) def tanh (x ): return np.tanh(x) input_data = np.random.randn(1000 , 100 ) node_num = 100 hidden_layer_size = 5 activations = {} x = input_data for i in range (hidden_layer_size): if i != 0 : x = activations[i-1 ] w = np.random.randn(node_num, node_num) * 1 a = np.dot(x, w) z = sigmoid(a) activations[i] = z for i, a in activations.items(): plt.subplot(1 , len (activations), i+1 ) plt.title(str (i+1 ) + "-layer" ) if i != 0 : plt.yticks([], []) plt.hist(a.flatten(), 30 , range =(0 ,1 )) plt.show()
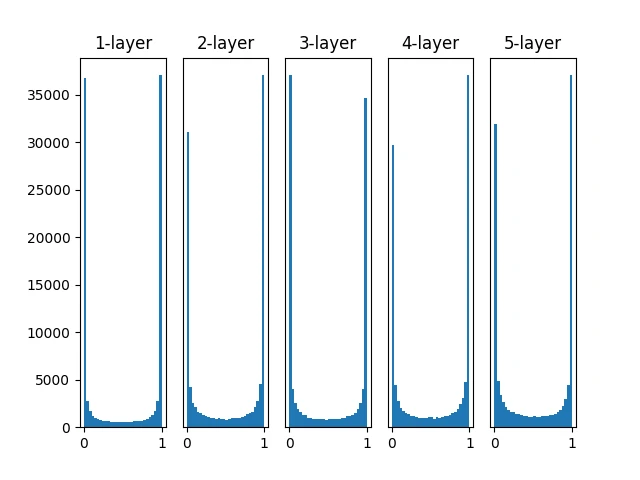
通过上述代码我们可以得到如下的数据分布图。其记载了一个 5 层神经网络,每层有 100 个神经元,激活函数使用 sigmoid,传入标准正态分布 随机生成的数据后,用直方图绘制各层激活值的数据分布。
如上图,各层的激活值呈现偏向 0 和 1 的分布
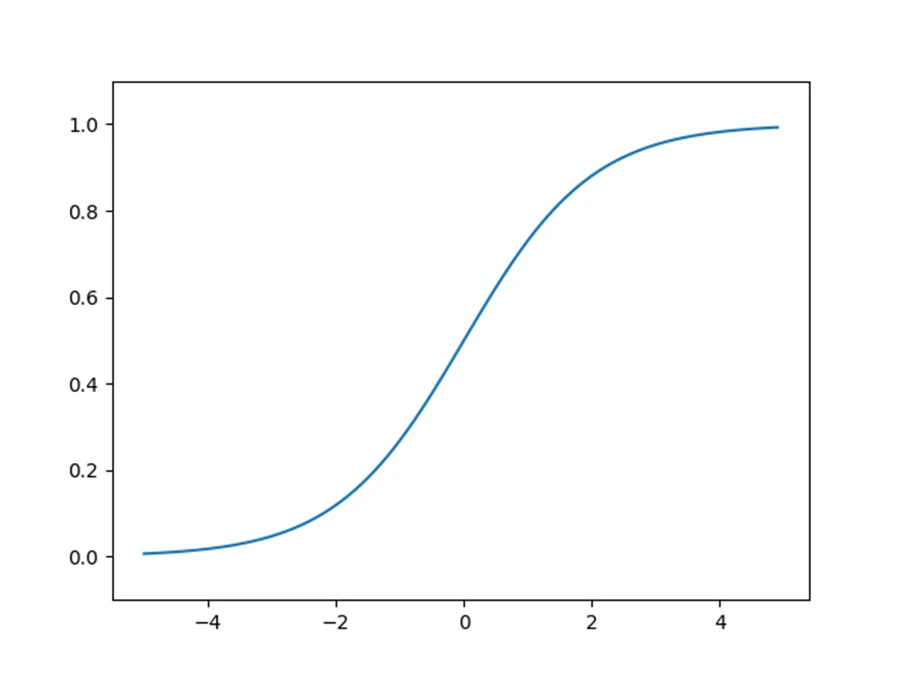
这是 sigmoid 函数的图像,可见它是一个 S 型函数,随着输出不断地靠近0(或者靠近1),它的导数的值逐渐接近0。因此,偏向0和1的数据分布会造成反向传播中梯度的值不断变小,最后消失。这个问题称为梯度消失 (gradient vanishing)。层次加深的深度学习中,梯度消失的问题可能会更加严重。
那如果将高斯分布的标准差设为 0.01 呢?
1 w = np.random.randn(node_num, node_num) * 0.01
这次呈集中在0.5附近的分布。因为不像刚才的例子那样偏向0和1,所以不会发生梯度消失的问题。但是,激活值的分布有所偏向,说明在表现力上会有很大问题。
因为如果有多个神经元都输出几乎相同的值,那它们就没有存在的意义了。比如,如果100 个神经元都输出几乎相同的值,那么也可以由1个神经元来表达基本相同的事情。因此,激活值在分布上有所偏向会出现“表现力受限”的问题 。
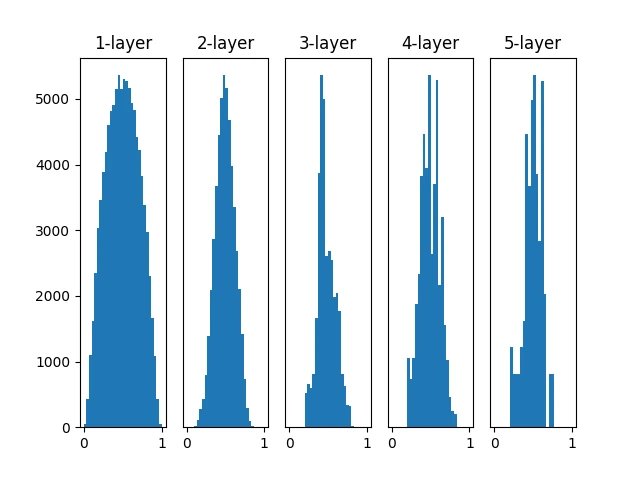
Xavier 初始值
Xavier Glorot 等人在论文中推荐了一种权重初始值,俗称“Xavier 初始值”。现在,在一般的深度学习框架中,Xavier 初始值已被作为标准使用。其推导出的结论是,如果前一层的节点数为 n,则初始值使用标准差为 1 n \frac1{\sqrt{n}} n 1 。
显然,前一层节点数越多,n 越大,则方差越小,因此初始值的尺度就越小
[!warning]线性函数 为前提推导出的
将上文代码中的权重改为
1 w = np.random.randn(node_num, node_num) * np.sqrt(1.0 / node_num)
越是后面的层,图像变得越歪斜,但是呈现了比之前更有广度的分布。因为各层间传递的数据有适当的广度,所以 sigmoid 函数的表现力不受限制,有望进行高效的学习。
[!tip]
ReLU 的权重初始值
当激活函数使用 ReLU 时,一般推荐使用 ReLU 专用的初始值,也就是 Kaiming He 等人推荐的初始值,也称为 “He 初始值” 。
当前一层的节点数为 n 时,He 初始值使用标准差为 2 n \sqrt{\frac2{n}} n 2
可以理解为,因为 ReLU 函数值域为非负数,因此为了使其具有更大的广度,需要使用 Xavier 初始值的 2 倍(更大的方差,更大的尺度)
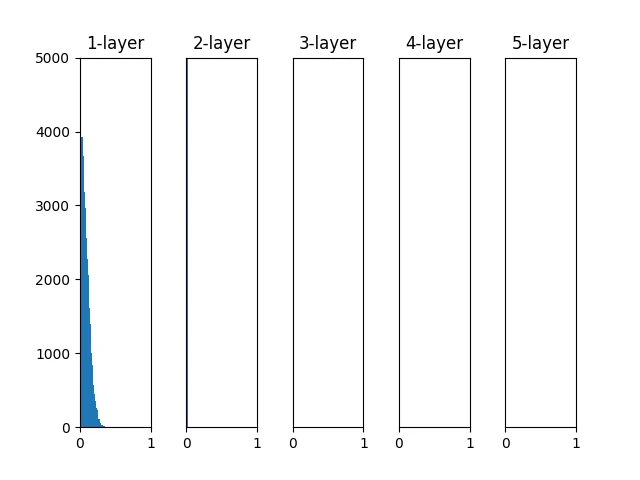
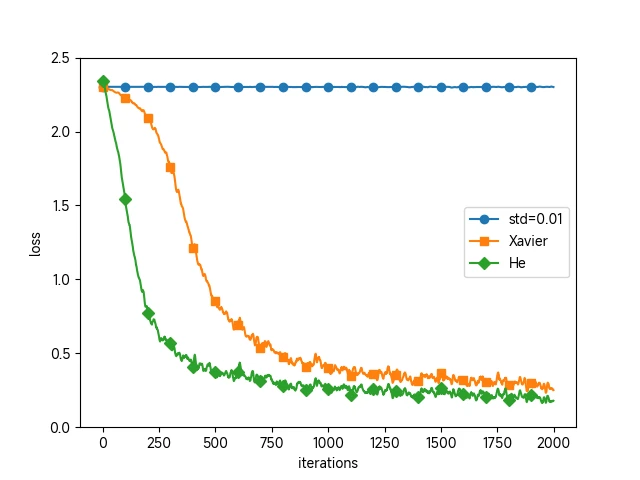
权重初始值为标准差是 0.01 的高斯分布时
神经网络上传递的是非常小的值,说明逆向传播时权重的梯度也同样很小。这是很严重的问题,实际上学习基本上没有进展。
权重初始值为 Xavier 初始值时
随着层的加深,偏向一点点变大。实际上,层加深后,激活值的偏向变大,学习时会出现梯即便层加深,数据的广度也能保持不变,因此逆向传播时,也会传递合适的值。度消失的问题。
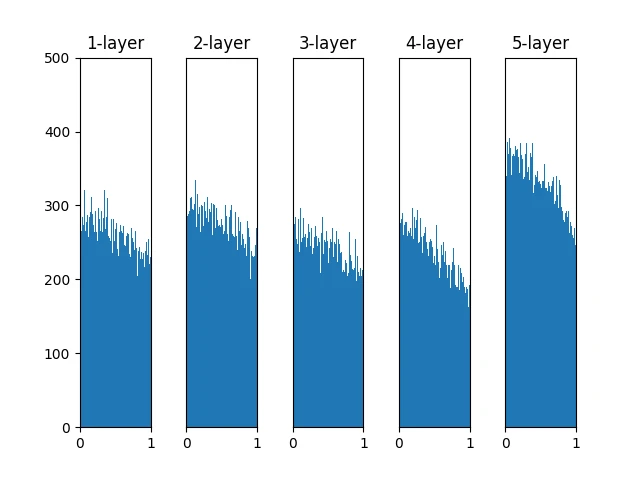
权重初始值为 He 初始值时
即便层加深,数据的广度也能保持不变,因此逆向传播时,也会传递合适的值。
基于 mnist 数据集的权重初始值比较
标准差为 0.01 的正态分布压根没法学习,损失函数动都不动
Xavier 和 He 效果很好,且 He 学习进度更快(loss 下降的更快)
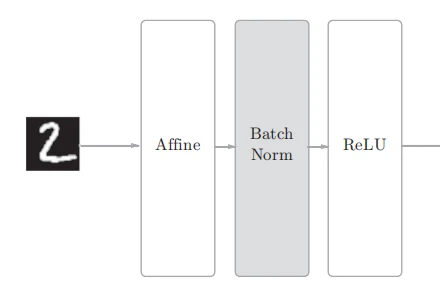
Batch Normalization
Batch Normalization(批量归一化) 的思路是调整各层的激活值分布使其拥有适当的广度, 因此在 affine 层与 ReLU 层之间添加一个 Batch Norm 层以对神经网络中的数据进行正规化。
其具体操作如下
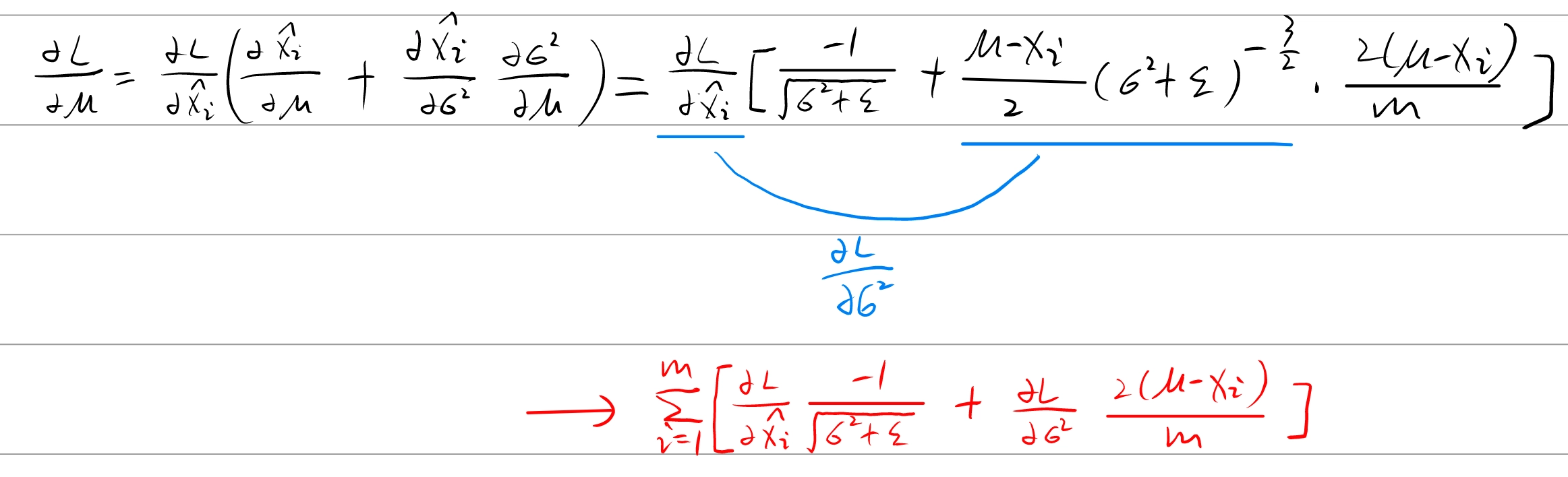
μ B ← 1 m ∑ i = 1 m x i σ B 2 ← 1 m ∑ i = 1 m ( x i − μ B ) 2 x i ^ ← x i − μ B σ B 2 + ϵ \begin{align}
\mu_B & \leftarrow \frac1m \sum_{i=1}^m x_i \\
\sigma_B^2 & \leftarrow \frac1m \sum_{i=1}^m (x_i - \mu_B)^2 \\
\hat{x_i} & \leftarrow \frac{x_i - \mu_B}{ \sqrt{\sigma_B^2 + \epsilon} }
\end{align}
μ B σ B 2 x i ^ ← m 1 i = 1 ∑ m x i ← m 1 i = 1 ∑ m ( x i − μ B ) 2 ← σ B 2 + ϵ x i − μ B
这里对 mini-batch 的 m 歌输入数据的集合 { x 1 , x 2 , . . . , x m } \{x_1, x_2, ..., x_m\} { x 1 , x 2 , ... , x m } μ B \mu_B μ B σ B 2 \sigma_B^2 σ B 2 x i x_i x i 正规化 为均值为 0,方差为 1 的数据 { x 1 , x 2 , . . . , x m ^ } \{\hat{x_1, x_2, ..., x_m}\} { x 1 , x 2 , ... , x m ^ } 减小数据分布的倾向 。ϵ \epsilon ϵ
接着,Batch Norm 层会对正规化后的数据进行缩放和平移 的变换,用数学式可以如下表示
y i ← γ x i ^ + β y_i \leftarrow \gamma \hat{x_i} + \beta
y i ← γ x i ^ + β
这里, γ \gamma γ β \beta β γ = 0 \gamma = 0 γ = 0 β = 1 \beta = 1 β = 1
推导过程详解
反向传播初始梯度为 ∂ L ∂ y i \frac {\partial L} {\partial{y_i}} ∂ y i ∂ L
需要计算 ∂ L ∂ x i \frac {\partial L} {\partial{x_i}} ∂ x i ∂ L ∂ L ∂ γ \frac {\partial L} {\partial \gamma} ∂ γ ∂ L ∂ L ∂ β \frac {\partial L} {\partial \beta} ∂ β ∂ L
论文中,作者将 ∂ L ∂ x i \frac {\partial L} {\partial{x_i}} ∂ x i ∂ L
∂ L ∂ x i = ∂ L ∂ x i ^ ∂ x i ^ ∂ x i + ∂ L ∂ σ 2 ∂ σ 2 ∂ x i + ∂ L ∂ μ ∂ μ ∂ x i \frac {\partial L} {\partial{x_i}} = \frac {\partial L} {\partial{\hat{x_i}}} \frac {\partial \hat{x_i}} {\partial{x_i}} + \frac {\partial L} {\partial{\sigma^2}} \frac {\partial \sigma^2} {\partial{x_i}} + \frac {\partial L} {\partial{\mu}}\frac {\partial \mu} {\partial{x_i}}
∂ x i ∂ L = ∂ x i ^ ∂ L ∂ x i ∂ x i ^ + ∂ σ 2 ∂ L ∂ x i ∂ σ 2 + ∂ μ ∂ L ∂ x i ∂ μ
下面是它们的推导过程
这里漏写了一个, ∂ μ ∂ x i = 1 m \frac {\partial \mu} {\partial x_i} = \frac 1 m ∂ x i ∂ μ = m 1
论文原文
过拟合
发生过拟合的原因,主要有以下两个。
例如从 MNIST 数据集原本的6w个训练数据中只选定300个
不使用权值衰减
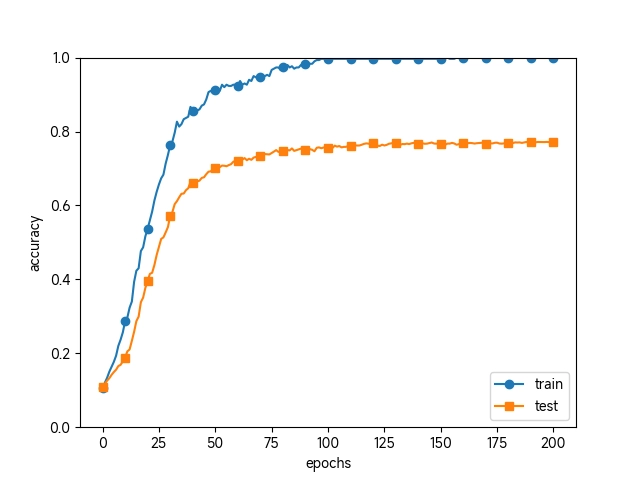
过了 100 个 epoch 左右后,用训练数据测量到的识别精度几乎都为 100%。但是,对于测试数据,离 100% 的识别精度还有较大的差距。如此大的识别精度差距,是只拟合了训练数据的结果。从图中可知,模型对训练时没有使用的一般数据(测试数据)拟合得不是很好。
权值衰减
权值衰减是一直以来经常被使用的一种抑制过拟合的方法。该方法通过在学习的过程中对大的权重进行惩罚,来抑制过拟合 。很多过拟合原本就是因为权重参数取值过大才发生的。
如果权值为 W W W 损失函数 加上权重的平方范数(L2范数 ),即 1 2 λ W 2 \frac12 \lambda W^2 2 1 λ W 2 误差反向传播法的结果 加上正则化项的导数 λ W \lambda W λW
λ \lambda λ 1 2 \frac12 2 1 1 2 λ W 2 \frac12 \lambda W^2 2 1 λ W 2 λ W \lambda W λW
1 2 3 4 5 6 7 8 9 10 11 def loss (self, x, t ): y = self .predict(x) weight_decay = 0 for idx in range (1 , self .hidden_layer_num + 2 ): W = self .params['W' + str (idx)] weight_decay += 0.5 * self .weight_decay_lambda * np.sum (W ** 2 ) return self .last_layer.forward(y, t) + weight_decay
使用了权值衰减
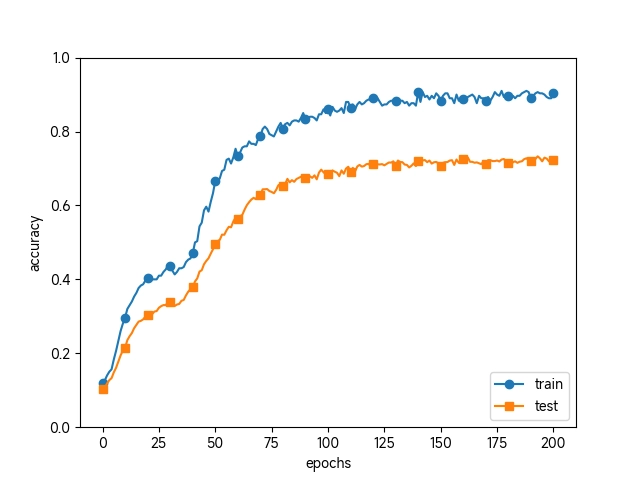
虽然训练数据的识别精度和测试数据的识别精度之间有差距,但是与没有使用权值衰减的结果相比,差距变小了。这说明过拟合受到了抑制 。
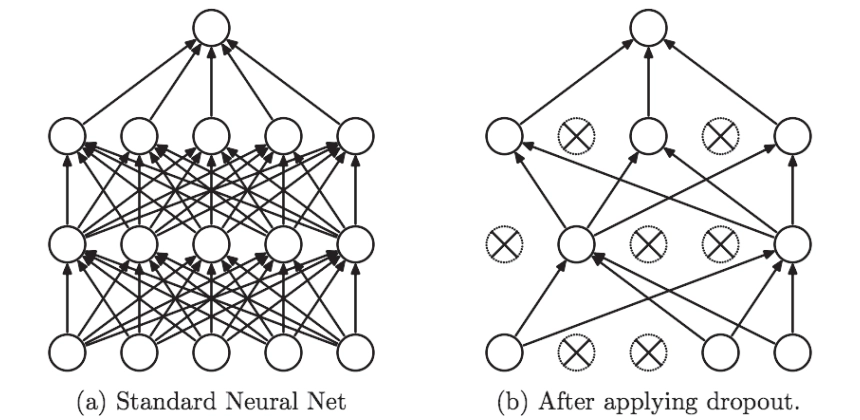
Dropout
Dropout 是一种在学习的过程中随机删除神经元 的方法。训练时,随机选出隐藏层的神经元,然后将其删除。被删除的神经元不再进行信号的传递 。训练时,每传递一次数据,就会随机选择要删除的神经元。然后,测试时,虽然会传递所有的神经元信号,但是对于各个神经元的输出,要乘上训练时的删除比例后再输出。
不听话?不听话就夹你!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Dropout : def __init__ (self, dropout_ratio=0.5 ): self .dropout_ratio = dropout_ratio self .mask = None def forward (self, x, train_flg=True ): if train_flg: self .mask = np.random.rand(*x.shape) > self .dropout_ratio return x * self .mask else : return x * (1.0 - self .dropout_ratio) def backward (self, dout ): return dout * self .mask
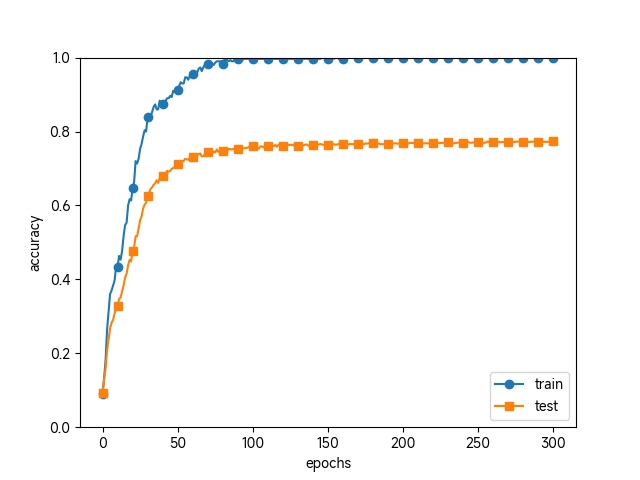
没有使用 Dropout
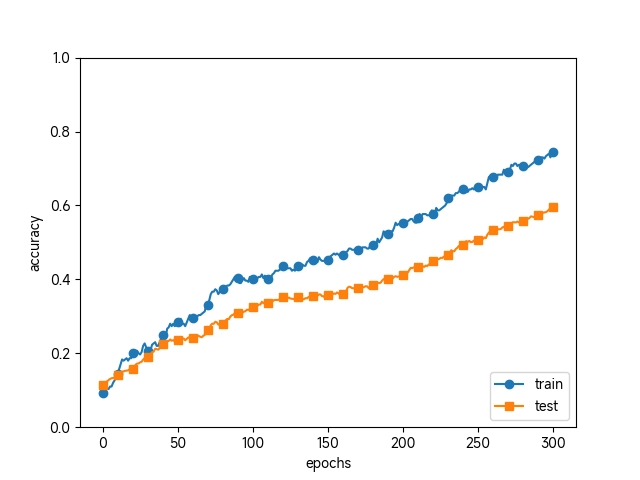
使用了 Dropout
通过使用 Dropout,即便是表现力强的网络,也可以抑制过拟合。
机器学习中经常使用集成学习 。所谓集成学习,就是让多个模型单独进行学习 ,推理时再取多个模型的输出的平均值。
用神经网络的语境来说,比如,准备 5个结构相同(或者类似)的网络,分别进行学习,测试时,以这 5个网络的输出的平均值作为答案。实验告诉我们,通过进行集成学习,神经网络的识别精度可以提高好几个百分点。
这个集成学习与 Dropout 有密切的关系。这是因为可以将 Dropout 理解为,通过在学习过程中随机删除神经元,从而每一次都让不同的模型进行学习 。并且,推理时,通过对神经元的输出乘以删除比例(比如,0.5等),可以取得模型的平均值。也就是说,可以理解成,Dropout 将集成学习的效果(模拟地)通过一个网络实现了。
超参数
超参数是指,比如各层的神经元数量、batch 大小、参数更新时的学习率或权值衰减等。如果这些超参数没有设置合适的值,模型的性能就会很差。
调整超参数时,必须使用超参数专用的确认数据,一般称为验证数据 (validation data)。我们使用这个验证数据来评估超参数的好坏。比较理想的是只用一次验证数据 。
[!warning]过拟合 !
根据不同的数据集,有的会事先分成训练数据、验证数据、测试数据三部分,有的只分成训练数据和测试数据两部分,有的则不进行分割。在这种情况下,用户需要自行进行分割。例如用训练数据的20%作为验证数据。
1 2 3 4 5 6 7 8 9 10 def shuffle_dataset (x, t ): """ 打乱数据集 """ permutation = np.random.permutation(x.shape[0 ]) x = x[permutation, :] if x.ndim == 2 else x[permutation, :, :, :] t = t[permutation] return x, t
超参数的范围只要 “大致地指定” 就可以了。所谓“大致地指定”,是指像0.001( 10 − 3 10^{−3} 1 0 − 3 10 3 10^3 1 0 3
1 2 3 4 weight_decay = 10 ** np.random.uniform(-8 , -4 ) lr = 10 ** np.random.uniform(-6 , -2 )
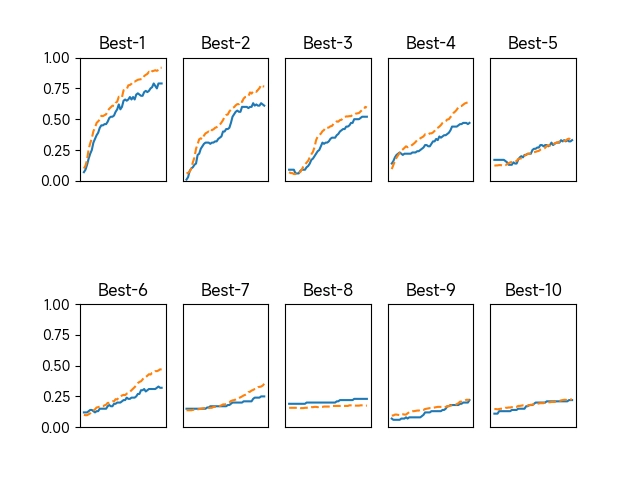
在超参数的最优化中,要注意的是深度学习需要很长时间 (比如,几天或几周)。因此,在超参数的搜索中,需要尽早放弃那些不符合逻辑的超参数。于是,在超参数的最优化中,减少学习的 epoch,缩短一次评估所需的时间是一个不错的办法。
1 2 3 4 5 6 7 Best-1(val acc:0.79) | lr:0.008381149872316536, weight decay:1.2740132675595203e-07 Best-2(val acc:0.61) | lr:0.006798932859815733, weight decay:5.427724799985068e-05 Best-3(val acc:0.52) | lr:0.003081830866896804, weight decay:3.424534700612302e-06 Best-4(val acc:0.47) | lr:0.003997839005016555, weight decay:1.3090155201683637e-06 Best-5(val acc:0.33) | lr:0.001760154887955398, weight decay:6.227114725290454e-07 Best-6(val acc:0.32) | lr:0.002993807782496189, weight decay:7.564414060749376e-07 Best-7(val acc:0.25) | lr:0.0018178836880097615, weight decay:1.4716823735556433e-05
例如一次训练后,我们发现学习率在0.001到0.01,权值衰减系数在 10 − 7 10^{-7} 1 0 − 7 10 − 5 10^{-5} 1 0 − 5







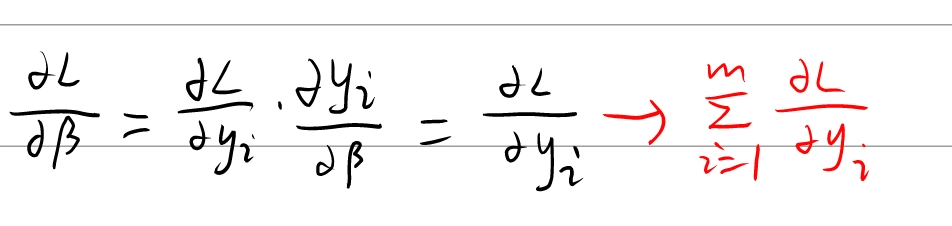
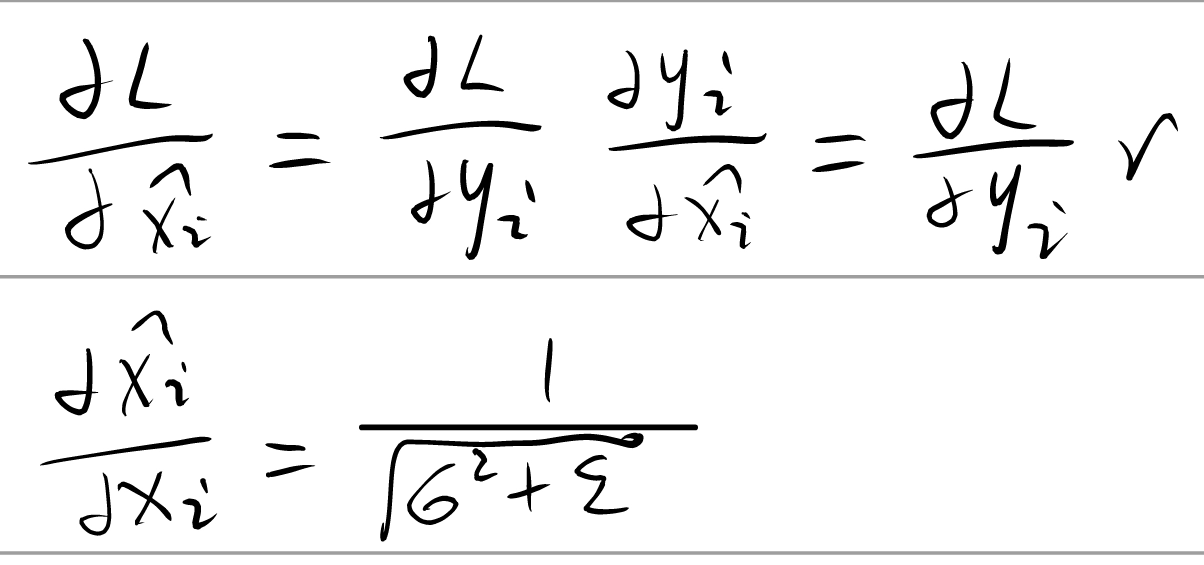
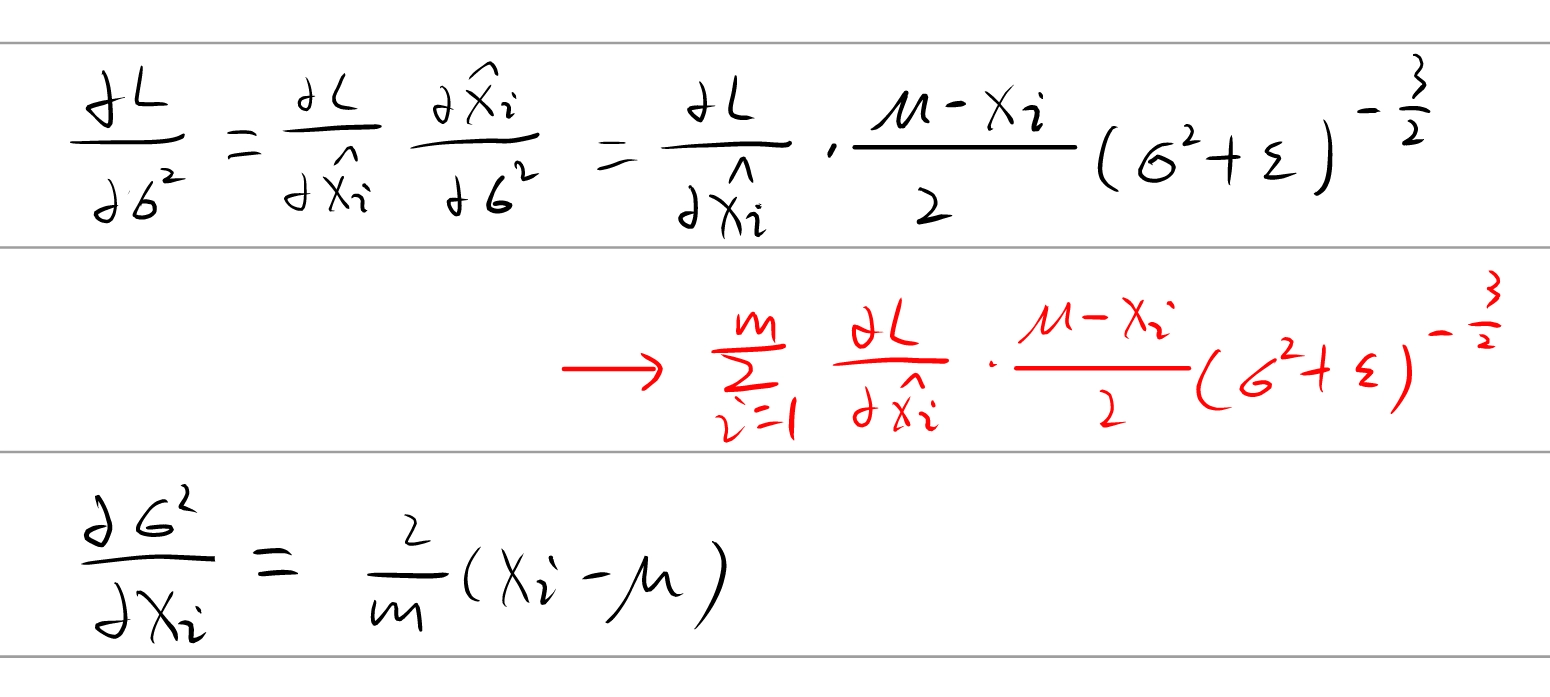

 微信
微信
